
Gartner有个预测:2026年,40%的企业应用将引入AI Agent。而就在2025年,这个数字还不到5%。
这个增速本身不让我意外。让我不安的是另一个数字——同期有研究指出,超过40%的Agentic AI项目可能在2027年前被叫停,原因是成本失控和扩展困难。
两个40%放在一起,意味着什么?
意味着大量团队正在同一个坑里犯同一类错误。他们不是输在模型选择上,也不是输在Prompt质量上——他们输在架构选择上。用了一个不该用的设计模式,或者没用该用的,或者把五个模式叠在一起,结果系统复杂度爆炸、延迟无法接受、Token成本失控。
我观察过很多团队的Agent项目,发现一个共同规律:失败的Agent系统,往往死于过度设计;成功的Agent系统,往往赢在恰到好处的克制。
设计模式不是越多越好,也不是越复杂越高级。它本质上是一张失败模式与解决方案的对照表。你得先知道自己在哪里失败,才能选对哪个模式来解决。
这篇文章,我想从基础到高级,一次讲透13种主流Agent设计模式的为什么、什么时候用、怎么实现。
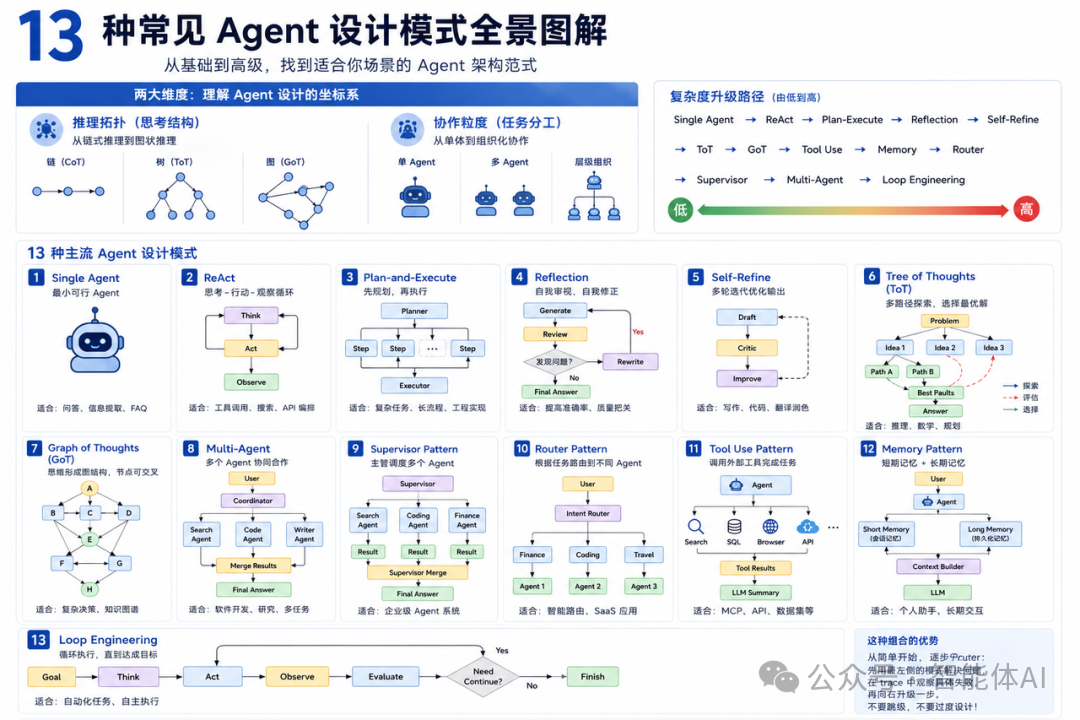
一、在进入13种模式之前,先建一张坐标系
很多人看到这张图的第一反应是:这么多模式,我从哪里开始?
这个问题本身就问错了。
正确的问题是:我的Agent在哪个环节失败了?
13种模式不是13个并列选项,让你从中挑一个。它们是按照不同失败场景分类的解法,有层次、有依赖、有演化逻辑。
理解这个坐标系,需要先建立两条轴:
︱第一条轴:推理拓扑
从Chain of Thought(链)到Tree of Thoughts(树),再到Graph of Thoughts(图)——这条演化线描述的是Agent"思考结构"的维度升级。
链状推理提交给一条路走到底,遇到岔路口就失效了。树状推理允许在每个节点探索多个分支,选最优路径前进,但最终还是"选一条路"。图状推理则允许不同分支的中间结论相互合并、相互引用——这才是真实复杂问题的推理拓扑。
︱第二条轴:协作粒度
从单个Agent独立完成所有工作,到多个Agent按角色分工协作,再到有明确调度层的层级组织——这条轴描述的是"任务分工"的粒度。
单Agent能解决的问题,一定不要上多Agent。每引入一个Agent就意味着多一条通信链路、多一个潜在失败点、多一倍的调试复杂度
1.Single Agent——最小可行Agent,也是最容易被低估的
很多工程师一上来就想搭复杂的多Agent系统,觉得单Agent太简单、不够高级。
这是一个代价很高的误判。
︱为什么这样设计
Single Agent的核心假设是:任务边界清晰,输入输出明确,不需要与外部世界动态交互。在这个前提下,给一个Agent足够好的System Prompt,它能做到的事情远超大多数人的想象。
加复杂架构有成本。每一层抽象都会带来延迟、引入新的失败点、增加调试难度。在任务本身不需要复杂度的时候,最聪明的选择就是什么都不加。
︱什么时候用
问答机器人、FAQ检索、客服第一层、固定格式的信息提取——凡是任务边界清晰、不需要工具调用、不需要多轮动态推理的场景,Single Agent就够了。
︱怎么实现
核心工作全在Prompt质量上,而不是架构设计上。一个好的System Prompt需要做到:角色定义清晰、能力边界明确、输出格式约束精准、边界案例有示例覆盖。
不要因为想展示技术复杂度就给一个简单任务套上ReAct循环——那是在为自己制造麻烦。
2.ReAct(Reason + Act)——生产环境的默认起点,不是终点
ReAct是2026年生产环境部署最广泛的单Agent模式,没有之一。但很多团队对它的理解停留在"思考-行动-观察"的表面,没有真正理解它解决的是什么根本问题。
︱为什么这样设计
标准LLM面临一个根本性的双重局限:它会推理,但不能与外部世界交互;它能调工具,但没有连贯的策略指导工具调用。
这两个局限分开来看都不致命,合在一起就很麻烦——Agent要么在凭空想象(幻觉),要么在盲目调用工具(无策略)。
ReAct的解法是把"思考"和"行动"编织成一个严格交替的循环:先想为什么要调这个工具,调完了把结果写进观察,再基于观察更新下一步思考。
这个结构有两个副产品,都很有价值:第一,可审计性——每一步决策都有Thought记录,出错了能追溯;第二,幻觉抑制——Agent必须在观察到工具结果之后才能继续推理,没办法凭空编造。
在受监管行业(金融、医疗、法律),这个可审计的Thought链本身就是合规要求的一部分,不是可选项。
︱什么时候用
搜索增强型问答(需要实时信息)、数据库动态查询(SQL需要根据结果调整)、多步API编排、任何需要工具调用且下一步依赖上一步结果的场景。
一个判断标准:如果你的任务需要调用工具,而且下一步该调什么工具取决于上一步的结果——上ReAct。
︱怎么实现
System Prompt的设计是核心。需要明确定义:可用工具列表(名称、描述、参数Schema)、强制输出格式(Thought: / Action: / Observation:)、循环终止条件。
循环控制上有三个必须做的事:设置最大迭代次数(建议10-15次,防止无限循环)、检测Final Answer关键词终止循环、工具调用失败时将错误信息写入Observation继续推理而不是直接崩溃。
一个经常被忽视的性能陷阱:ReAct每一轮都需要一次完整的LLM调用,延迟随步骤数线性增长。如果你的场景对延迟敏感,要么控制最大步骤数,要么在执行层用更快的小模型——让强模型负责推理,弱模型负责工具调用。
3.Plan-and-Execute——当"走一步看一步"开始拖累效率
很多人第一次接触Plan-and-Execute时会问:这和ReAct有什么本质区别?都是思考然后执行。
区别在于规划与执行的分离时机。
︱为什么这样设计
ReAct是完全的在线规划——每一步都要重新推理下一步该做什么。这在探索性任务上是优势(因为下一步真的依赖当前观察),但在结构化的长任务上是劣势——你每一步都在付出完整的LLM推理成本,哪怕这一步的决策在任务开始时就已经可以确定了。
Plan-and-Execute的洞察是:很多复杂任务是可以事先分解的。先用一个强模型生成完整的执行计划(DAG结构的任务依赖图),然后按照计划顺序或并行地执行各子任务——执行层甚至可以用更便宜的小模型。
这个分离带来两个直接收益:成本下降(强模型只用一次)和速度提升(独立子任务可以并行)。有数据支撑:Plan-and-Execute架构相比顺序ReAct执行,任务完成率可达92%,速度提升约3.6倍。
︱什么时候用
复杂研究任务(需要并行搜集多个子主题)、代码工程任务(先设计架构再分模块实现)、自动化数据处理流水线、任何能被明确分解成有序子任务的长工作流。
判断标准:如果你的任务超过5个步骤,而且这些步骤在任务开始时就基本可以预见——用Plan-and-Execute,不要用ReAct。
︱怎么实现
两阶段架构:
第一阶段,Planner(用强模型)——接收用户目标,输出JSON格式的任务DAG,包含每个子任务的描述和依赖关系。这个JSON是整个执行的契约,格式要严格,便于后续程序解析。
第二阶段,Executor(可以用轻量模型)——按依赖关系顺序或并行执行各子任务,每个子任务内部可以是一个ReAct循环。
重规划机制是这个模式的关键安全阀:当子任务连续失败超过N次,或者观察到的环境状态与预期不符时,把当前状态重新交给Planner生成新的计划,而不是让系统在错误的轨道上继续跑。
需要注意的是:计划生成阶段本身引入了一次额外的LLM调用,如果你的任务是3步以内的简单工作流,这个开销得不偿失,直接用ReAct就好。
4.Reflection——给输出质量加一道自审关卡
︱为什么这样设计
LLM的第一次输出本质上是一次"最大似然猜测"——模型在给定上下文下选择最可能的下一个Token序列,但这个"最可能"并不等于"最正确"。
Reflection的核心洞察是:让同一个模型从批判者的角度审视自己的输出,往往能发现单次前向传递无法发现的问题。 这等效于为每次输出引入一轮代码Review——Review者和作者是同一个人,但换了视角。
有数据支持这个判断:Reflection设计模式在HumanEval编程基准上将准确率从80%提升到91%。如果结合外部验证工具(比如真正运行单元测试),提升幅度可以超过30个百分点。
︱什么时候用
长文写作、技术文档、代码生成、事实类问答——凡是"答错的代价高于答慢的代价"的场景,Reflection值得投入。
反过来说:如果你的场景对延迟极度敏感,而且容错率高,就不要加Reflection——它会引入一次额外的LLM调用。
︱怎么实现
两步架构。第一步Generator正常生成初始输出;第二步Reviewer(可以是同一个模型,但用完全不同的Prompt)从批判者视角审查:
Reviewer的Prompt设计至关重要——要求给出具体可操作的问题,而不是泛化批评;要按维度打分(准确性、完整性、逻辑一致性);要输出结构化JSON便于程序路由。
如果Reviewer判断需要重写,将具体问题注入Generator重新生成;否则直接输出。
进阶用法是引入外部验证器:代码场景跑单元测试、事实场景调搜索API验证关键声明、数学场景调计算器验证数值。外部验证器的结果比LLM自我评价更可靠,因为它是确定性的。
三、推理进阶三式:从链到树到图
在进入这三种模式之前,需要先说一个2026年的现实背景。
随着GPT5、Claude这类原生推理模型的成熟,ToT和GoT的使用门槛在提高——因为推理模型本身已经在内部做了类似的多路径探索,你未必需要在外部显式构建树或图结构来获得同样的效果。
但这不意味着ToT和GoT已经过时。它们在以下情况仍然不可替代:任务需要透明可解释的推理过程、你需要精确控制搜索预算、使用的是非推理模型、或者问题本身具有明确的图状拓扑结构。
5.Self-Refine——多轮迭代的质量飞轮
︱为什么这样设计
Reflection是一次性自检,Self-Refine把这个过程变成循环。每轮Critic都基于上一轮Improve的结果继续批评,形成质量飞轮效应。
类比人类写作:好文章不是写出来的,是改出来的。第一稿解决"有没有"的问题,第二稿解决"准不准"的问题,第三稿解决"好不好"的问题。Self-Refine就是把这个过程形式化为算法。
︱什么时候用
文章写作、邮件起草、方案撰写、代码质量打磨、翻译润色——任何需要反复雕琢、最终输出质量远比生成速度重要的创意型任务。
︱怎么实现
循环结构:Draft → Critic(打分+指出问题)→ Improve → Critic → …→ Final
终止条件必须三选一,避免无限循环:Critic评分超过阈值(比如8/10)、达到最大迭代次数(建议3-5轮)、两轮改进之间的差异低于阈值(收敛检测)。
Critic Prompt的设计决定了整个循环的质量上限。关键是要求给出具体可操作的改进意见,而不是"这里还不够好"这种泛化批评。最好要求分维度打分并输出结构化JSON,让程序能够自动判断是否继续循环。
6.Tree of Thoughts(ToT)——当推理需要在岔路口做选择
︱为什么这样设计
线性推理在遇到需要回溯的问题时会系统性失效。一旦走上了错误的路径,链式推理只能硬撑到底,因为它没有"退回来换一条路"的机制。
ToT的核心洞察是:把推理过程建模为一棵状态树,在每个节点评估多个候选后继状态,只沿最有前途的分支继续探索。 本质上是把"多角度思考后择优"这个人类认知过程形式化为算法。
有一个广为引用的数据:Game of 24谜题(用给定数字通过四则运算得到24),GPT-4单次CoT成功率只有4%,套上ToT框架后达到74%。这个数字说明了两件事:ToT在正确的场景下效果显著;但同时也暗示了它的成本——74%的成功意味着26%的失败还是存在的,而ToT的token消耗远高于单次CoT。
︱什么时候用
数学推理与证明、游戏与规划问题(需要前瞻性搜索)、策略制定(需要评估多个方案)、约束满足问题。
什么时候不用:如果你已经在用GPT5或Claude这类推理模型,它们内部已经做了类似的多路径搜索,外面再套ToT大概率是在为推理推理——成本翻倍,收益边际递减。先测一下推理模型的裸跑效果,再决定要不要上ToT。
︱怎么实现
三个核心组件缺一不可:
Thought Generator:给定当前状态,生成k个候选下一步(生产环境建议k=3,超过这个数字成本开始失控)。
State Evaluator:对每个候选状态打分。这里有一个工程技巧:能用确定性验证器的场景,绝对不要用LLM Judge。schema验证、单元测试运行、算术验证——这些确定性检查比LLM自我评价便宜10倍以上,而且更可靠。只在没有确定性验证器时才退而求其次用LLM打分。
Search Controller:BFS适合浅树(深度≤3),DFS适合需要快速找到可行解的场景,Beam Search是生产部署的首选——保留top-k最优分支,在质量和成本之间取得最好的平衡。
成本控制是ToT的生死线,不是可选项。必须设置硬上限:分支数b≤3,每节点评估k≤2,最大深度d≤2。对抗性输入会触发指数级分支爆炸——没有硬上限的ToT是一颗定时炸弹。
7.Graph of Thoughts(GoT)——当推理需要合并多路径的中间结论
︱为什么这样设计
ToT解决了"多路径探索"的问题,但它最终还是要"选一条最优路径"——这个约束在很多现实问题上是不成立的。
真实的复杂问题往往需要:把来自不同分支的子结论合并起来综合判断。比如写一份竞品分析报告,你需要同时从技术、产品、商业模式三个维度独立分析,然后把三个维度的结论合并成最终判断——这个过程在ToT的树结构里无法自然表达,但在GoT的图结构里完全自然。
GoT允许节点之间任意连接:分支(一个思维生成多个子思维)、聚合(多个思维合并成一个综合节点)、回环(对已有节点进行反馈精炼)——这是目前推理拓扑表达能力最强的形式。
有研究表明,在多跳推理和QA任务上,GoT比CoT/ToT基线准确率高出10至46个百分点。
︱什么时候用
复杂决策分析(需要综合多维度证据)、知识图谱推理、需要合并多个子结论的研究型任务、多Agent辩论后的共识形成。
GoT的实现复杂度显著高于ToT,不到万不得已不要上。先问自己:我的问题真的需要合并来自不同路径的中间结论吗?如果答案是否,ToT或ReAct就够了。
︱怎么实现
核心数据结构是一个有向图 G=(V, E),其中每个节点V是一次LLM生成或工具调用的结果,每条边E标注类型(supports/contradicts/refines/depends_on/merges)。
四类操作定义了图的演化方式:Generation(从父节点生成新子节点)、Aggregation(合并多个父节点)、Refinement(对现有节点做反馈迭代)、Distillation(剪枝低分节点)。
工程实现上推荐使用LangGraph的StateGraph原语——节点即思维状态,边的条件路由实现不同操作类型,每个节点存储content、score、operation_type、parent_ids这四个字段。
四、协作四式:多Agent的分工架构
在进入这四种模式之前,我想先说一个在生产环境观察到的反模式:大多数团队在单Agent远未触及天花板的时候就引入了多Agent。
判断标准只有一个:用traces观察,单Agent的哪个具体能力瓶颈在限制系统整体表现?是工具太多导致选择混乱?是上下文太长导致注意力稀释?还是职责太杂导致Prompt质量下降?找到这个瓶颈,才能判断引入多Agent能否真正解决问题。
协调多个Agent本身有开销——通信延迟、状态同步、错误传播——这些开销只有在分工收益大于协调成本的时候才合算。
8.Multi-Agent——最基础的协同模型
︱为什么这样设计
一个Agent同时负责搜索、写代码、写报告,它的System Prompt会变得极度复杂,工具列表会变得很长,注意力会被分散,每个职责的表现都会下降。
Multi-Agent的核心洞察是:专业化带来质量提升,而质量提升足以抵消协调成本。 Search Agent只关心检索质量,Code Agent只关心代码正确性,Writer Agent只关心文本表达——每个Agent在小上下文中处理自己最擅长的工作,系统整体性能反而更优。
︱什么时候用
软件开发任务(Search + Code + Writer协作)、多模态研究任务、需要并行处理的长工作流——任何单Agent因为职责过多而性能下降的场景。
︱怎么实现
Coordinator Agent负责接收用户请求、分解子任务、分发给专家Agent、收集结果、合并输出。每个Specialist Agent有独立的System Prompt和独立的工具集。
通信机制的选择影响系统整体延迟:同步模式(Coordinator等待所有Agent返回再合并)适合有依赖关系的任务;异步并行执行(设置超时与Fallback)适合独立子任务。
9.Supervisor Pattern——动态调度,而不是静态分发
︱为什么这样设计
Multi-Agent的Coordinator是静态的——它按照预设逻辑把任务分发给各个Agent,不会根据执行过程中的情况调整分配策略。
Supervisor Pattern引入了动态调度:Supervisor根据任务当前进展实时决定下一步派哪个Agent、传什么上下文、如何处理返回结果中的冲突。更接近现实团队中"项目经理"的角色——不只是传话筒,而是真正在管理任务进展。
︱什么时候用
企业级Agent系统、需要动态任务重分配的复杂工作流、存在依赖关系的多步骤任务、需要处理子任务失败并重新规划的场景。
︱怎么实现
Supervisor的核心是一个决策循环:基于当前状态决定下一步派哪个Agent、给什么指令,执行后更新状态,再次决策,直到任务完成。
几个关键设计点:
Supervisor的System Prompt必须包含所有子Agent的完整能力描述,让它能做出准确的调度决策
每次子Agent调用后向Supervisor传递结果摘要而非全文,控制Supervisor的上下文窗口不要膨胀
设计明确的"任务完成"判断标准,避免Supervisor陷入无意义的循环
子Agent的返回值必须是结构化格式,便于Supervisor解析和路由
10.Router Pattern——在入口层做好意图分发
︱为什么这样设计
一个通用Agent试图覆盖所有业务域,结果是每个域都表现平庸。Router的解法是在最前端做意图识别,把请求精准路由到最合适的专域Agent——"专家接待"而不是"全科医生"。
这个模式解决的不是执行问题,而是分发问题。路由准确性决定了后续所有Agent的工作质量上限。
︱什么时候用
SaaS平台(Finance/HR/IT等业务线各有专属Agent)、多业务线客服系统、任何需要根据用户意图动态选择处理路径的系统。
︱怎么实现
三种实现方案,按精度与成本排序:
Embedding分类器:最快最便宜,把用户输入做embedding,与各Agent描述的embedding做相似度匹配。适合意图边界清晰的场景。
LLM分类:精度更高,让LLM明确判断应该路由到哪个Agent并输出置信度。当置信度低于阈值(建议0.7)时路由到通用Agent或人工兜底。
多标签路由:用于复杂请求同时涉及多个业务域的情况,Router输出路由计划而非单一目标,由后续的Supervisor协调执行。
保留路由决策日志是必须的,这是后续持续优化路由准确性的数据基础。
11.Memory Pattern——解决AI最大的架构缺陷
︱为什么这样设计
LLM无跨会话记忆是AI Agent最大的架构缺陷之一,也是用户体验最大的痛点之一。"我上次告诉你我是做什么的,你怎么又不知道了?"
Context Window是短期记忆,会话结束就消失。Memory Pattern通过外部存储实现长期记忆持久化,并在每次请求时通过Context Builder动态注入相关记忆,让Agent具备真正的"认识你"的能力。
︱什么时候用
个人AI助手、长期项目协作Agent、客户关系管理、任何需要跨会话状态保持的系统。如果你的用户需要反复自我介绍,你就需要Memory Pattern。
︱怎么实现
双轨架构:
Short Memory(会话级):当前对话历史和本次工具调用结果,存在messages数组中,随上下文传递,会话结束消失。
Long Memory(持久化):按照记忆类型选择存储层——语义记忆用向量数据库(pgvector、Pinecone、Weaviate),结构化记忆(用户偏好、历史决策)用关系数据库,情节记忆(具体事件的时序记录)用KV存储。
Context Builder是Memory Pattern的核心:对用户当前输入做embedding,从向量库检索top-k相关历史记忆,格式化后注入System Prompt。注意:检索相关记忆,而不是注入所有记忆——上下文窗口有限,注入无关记忆反而有害。
记忆写入时机同样重要:不要把整段对话原文写进长期记忆,而是在对话结束时用LLM提炼关键信息,过滤噪声,只存结构化的关键事实。
五、终极形态:Tool Use Pattern与Loop Engineering
12.Tool Use Pattern——连接真实世界的接口层
︱为什么这样设计
LLM的知识是静态的(训练截止日期之前的世界),而真实世界是动态的。Tool Use Pattern把外部能力(搜索、数据库、浏览器、API、代码执行器)标准化为Agent可调用的接口,让Agent从"封闭的知识库"进化为"能与世界交互的行动者"。
2026年的结构化工具调用已经成熟:LLM返回与预定义JSON Schema匹配的结构化参数,而不是需要解析的自由文本指令。这个进步消除了大量脆弱的文本解析代码。
︱什么时候用
MCP集成、API自动化、数据库查询生成、浏览器操作——任何需要Agent与外部系统交互的场景。Tool Use不是一个独立的设计模式,它通常是ReAct、Plan-and-Execute等模式的执行层基础设施。
︱怎么实现
工具定义的质量决定了工具使用的效果,工具描述质量 > 工具数量。一个描述不清的工具比没有工具更危险,因为Agent可能在不该调用的时候调用它。好的工具描述需要包含:工具的能力边界(能做什么、不能做什么)、适用场景(什么时候该用它)、参数说明(每个参数的含义和约束)。
四阶段执行循环缺一不可:LLM选择工具并生成调用参数(结构化JSON)→ Schema验证(防止参数错误导致下游崩溃)→ 工具执行并捕获异常 → 将结果作为tool_result注入对话触发下一轮推理。
有一个工程实践很容易被忽视:多个相互不依赖的工具调用可以并发执行,而不是顺序排队。这一个改动有时候能让整体延迟降低50%以上。
13.Loop Engineering——最高层的控制抽象,也是风险最高的模式
Loop Engineering是整个能力框架的顶点,也是我在这13种模式中最想花时间讲清楚的一个。
︱为什么这样设计
前面12种模式都是有限执行的——调用次数有上限,推理路径有终点。Loop Engineering不一样:它是目标驱动的持续循环,Agent在Goal的驱动下不断执行Think→Act→Observe→Evaluate,直到自己判断目标已经达成。
这是实现真正"自主执行"的核心机制。没有Loop Engineering,你搭的是一个工具,有了Loop Engineering,你搭的才是一个真正的Agent。
但也正因为如此,它是风险最高的模式。一个没有做好安全设计的Loop Engineering系统,轻则无限循环消耗Token,重则在没有人监督的情况下执行了不该执行的操作。
︱什么时候用
长时自动化任务、无人值守的自主执行工作流、需要持续监控与响应的后台Agent——任何需要Agent自主决定"是否继续执行"的场景。
︱怎么实现
核心结构是一个目标驱动的While循环:
state = {goal, context, history, iteration_count, cost_so_far}
whileTrue:
thought = llm.think(state) # Think:推理下一步
action_result = execute(thought) # Act:执行行动
state.update(action_result) # Observe:更新状态
evaluation = llm.evaluate(state) # Evaluate:判断是否继续
ifnot evaluation.need_continue:
break
if state.iteration_count > MAX_ITER:
break# 强制终止,输出当前最优结果
if state.cost_so_far > COST_LIMIT:
break # 成本告警并终止安全设计不是可选项,是Loop Engineering的生死线:
最大迭代次数硬限制:这个必须是硬编码的常量,不能是LLM可以修改的变量。建议根据任务复杂度设定,一般20-50次。
成本累计监控:Token消耗超过预设阈值时强制告警并终止,防止成本失控。
幂等性设计:同一个Action重复执行结果应该一致,这样在系统恢复时可以安全重放。
检查点机制:定期保存当前state到持久化存储,支持断点续跑,避免因为临时错误导致所有进度丢失。
Human-in-the-Loop插入点:高风险操作(删除数据、发送邮件、执行支付)执行前必须请求人类确认。自主不等于无监督,这条线不能随意突破。
六、推荐组合架构:拆解每一层的选型理由
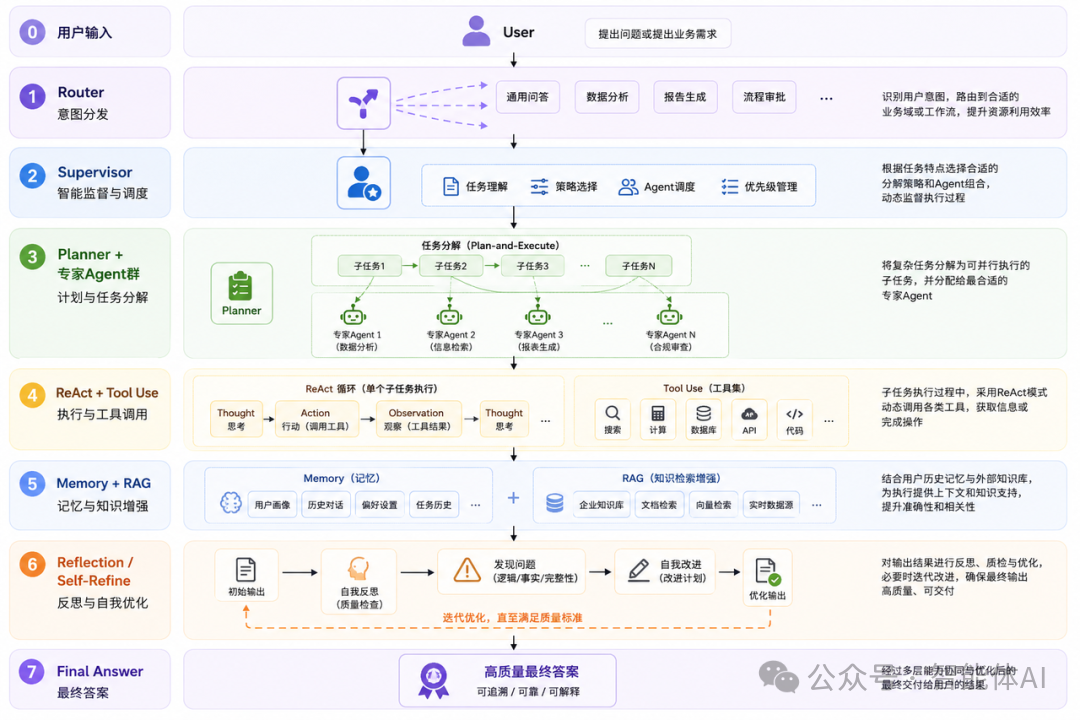
我来逐层解释为什么是这个组合,而不是别的。
Router在最前端:因为意图分发的准确性决定了后续所有计算资源的使用效率。错误路由意味着后面所有的工作都是浪费。
Supervisor在第二层:因为不同的业务请求需要不同的任务分解策略和Agent调度逻辑,静态的Coordinator无法适应这种动态性。
Plan-and-Execute在规划层:因为进入到具体执行阶段的任务通常已经足够复杂,需要先分解再并行执行,而不是ReAct式的逐步探索。
ReAct + Tool Use在执行层:因为单个子任务的执行仍然可能需要动态工具调用,ReAct是单步可靠执行的最佳模式。
Memory + RAG在记忆层:因为企业级Agent需要同时具备用户历史记忆(Memory)和知识库检索能力(RAG),两者相辅相成。
Reflection/Self-Refine在最后:因为输出质量是最终交付给用户的东西,在这里做最后的质检,性价比最高。
需要强调的是:这个组合架构不是所有场景的标准答案,而是一个适合复杂企业级工作流的参考模板。简单的问答场景,从这个链路里拿掉80%的组件,剩下的可能就够用了。
七、选模式的第一性原理:从症状反推
真正理解了这13种模式,选型逻辑应该是这样的:
先观察traces,找到失败点,然后对照:
工具调用无策略、结果不接地气 → ReAct
长任务执行混乱、步骤相互干扰 → Plan-and-Execute
输出质量不稳定、首次生成错误多 → Reflection
质量瓶颈需要多轮打磨 → Self-Refine
推理在分叉点卡死,需要多路径探索 → ToT
需要合并多个子问题的中间结论 → GoT
单Agent上下文膨胀、工具选择混乱 → Multi-Agent
任务分配需要根据执行情况动态调整 → Supervisor
不同类型请求需要不同专家处理 → Router Pattern
跨会话记忆丢失,用户需要反复自我介绍 → Memory Pattern
需要持续自主运行,无人值守 → Loop Engineering
这个表格比任何框架都重要。先找症状,再选药。 没有症状就不要用药。
八、写给工程师的实战备忘录
最后,整理几条在实际项目中反复验证过的工程原则:
永远先建ReAct基线,在评估集上测量成功率、工具调用准确率、延迟和成本,再决定是否升级到更复杂的模式。很多你以为需要复杂架构的问题,一个调优好的ReAct就能解决。
模式组合不是越多越好。每增加一个模式都会增加延迟、引入新的失败点、扩大调试范围。只在traces里观察到明确的失败时才加下一个模式——这是克制,不是偷懒。
框架选择按团队熟悉度。LangGraph、AutoGen、CrewAI、OpenAI Agents SDK在Q2 2026均已全面支持上述模式,不存在某框架独家支持某模式的情况。用你最熟悉的,学习曲线的成本远比框架特性差异更重要。
ToT/GoT适合有预算的场景。有原生推理能力的模型(Claude extended thinking、o3)在大多数场景下性价比更高。先测推理模型的裸跑效果,再决定要不要在外面套ToT。
Loop Engineering必须有完整的安全设计才能上生产。最大迭代次数、成本上限、幂等性、检查点、Human-in-the-Loop——缺任何一个,这个系统就不是自主Agent,是定时炸弹。
工具描述质量 > 工具数量。给Agent10个描述清晰的工具,比给它30个描述模糊的工具效果好得多。工具选择错误是ReAct和Tool Use Pattern最常见的失败模式之一,根源往往不是模型能力问题,而是工具描述问题。
九、总结
回到开头那两个40%。
2026年,40%的企业应用将引入AI Agent——这个趋势不会改变。但同样有40%以上的项目会以成本失控或架构失败告终。
分开这两个40%的,不是模型选择,不是工具链选择,是架构判断力。
13种设计模式,本质上是13种失败场景的解法。真正掌握它们的标志,不是能把每种模式的定义背出来,而是当你在traces里看到一个具体的失败,能立刻知道该用哪个模式、为什么、怎么实现。
这是从使用者到设计者的分水岭,也是Agent工程师真正的护城河。