

一、GraphRAG概念
GraphRAG = Graph + RAG,是将知识图谱与检索增强生成相结合的技术范式。
传统RAG主要依靠向量相似度检索文本块,而GraphRAG在向量检索之外,引入了图结构来捕获实体之间的关联关系,从而实现对知识更深层的理解和推理。
核心思想:将非结构化文本转化为结构化知识图谱,利用图结构辅助检索,让LLM的回答更准确、更全面、更可解释。
二、GraphRAG系统架构
核心设计理念:离线构建 + 在线检索双阶段架构
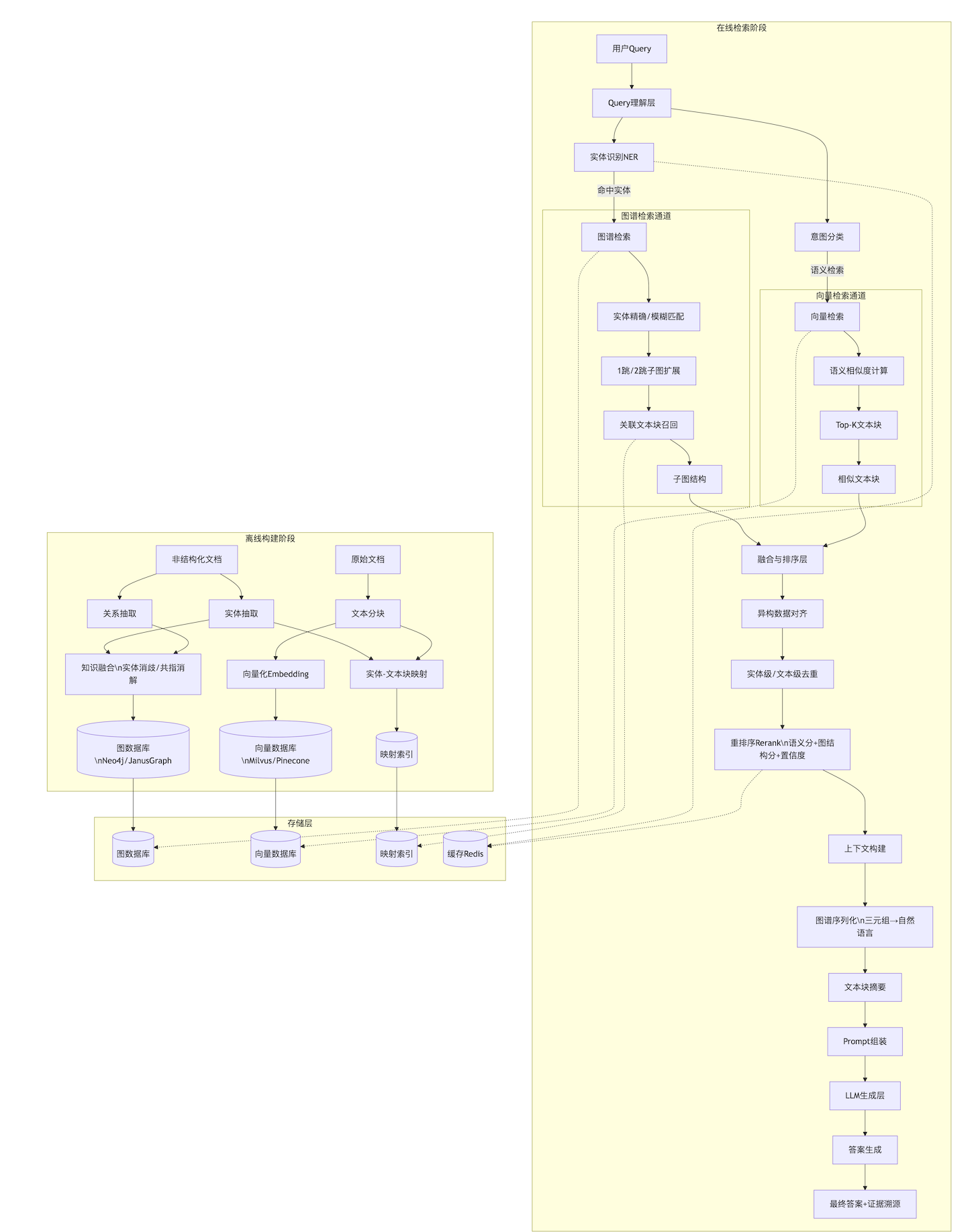
┌─────────────────────────────────────────────────────────┐
│ 离线构建阶段 │
├─────────────────────────────────────────────────────────┤
│ 非结构化数据 → 知识图谱构建 → 向量化 → 存储 │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 在线检索阶段 │
├─────────────────────────────────────────────────────────┤
│ 用户Query → Query理解 → 混合检索 → 融合 → 生成 │
└─────────────────────────────────────────────────────────┘1、离线构建层(Knowledge Base Construction)
目标:将原始文档转化为结构化的、可检索的知识表示
1.1 知识图谱构建模块
【输入】非结构化文本/多模态文档
【流程】
├─ 实体抽取(LLM/NER模型):识别人名、公司、产品、地点、概念等
├─ 关系抽取:提取实体间的语义关系("任职于"、"竞争对手"、"位于")
├─ 属性抽取:实体本身的属性(成立时间、员工数、市值)
├─ 知识融合:
│ ├─ 实体消歧(同名不同指)
│ └─ 共指消解(代词指向实体)
└─ 图谱存储:图数据库(Neo4j/JanusGraph/Amazon Neptune)
【输出】三元组库(头实体-关系-尾实体)+ 属性图1.2 向量索引构建模块
【输入】原始文档块/实体描述文本
【流程】
├─ 文本分块(chunking):段落/语义单元切分
├─ 向量化(Embedding):text-embedding-3-large等模型
└─ 向量存储:Milvus/Pinecone/Weaviate/Qdrant
【输出】向量索引库 + 文本块元数据1.3 元数据关联层(关键设计)
建立【实体】←→【文本块】的映射关系
目的:图谱检索命中实体后,可快速召回原始证据文本
存储:倒排索引/关系表2、在线检索层(Online Retrieval)
目标:理解用户意图,从异构数据源中召回最相关信息
2.1 Query理解模块
【输入】用户自然语言Query
【处理】
├─ 意图识别:事实问答/推理问答/总结类
├─ 实体识别(NER):提取Query中的关键实体
└─ 关系解析:识别Query隐含的关系约束
【输出】结构化查询意图(实体集 + 问题类型)2.2 混合检索模块(并行执行)
检索通道A:图谱检索
【触发条件】Query命中知识图谱中的实体
【检索策略】
├─ 精确匹配:实体名称完全匹配
├─ 模糊匹配:同义词/别名扩展
├─ 子图扩展:1跳/2跳邻域检索
│ ├─ 一跳:直接关联实体+关系
│ └─ 多跳:路径检索(用于推理类问题)
└─ 属性检索:实体属性值过滤
【输出】子图结构(实体-关系-实体)+ 关联文本块检索通道B:向量检索
【触发条件】始终执行(作为召回补充)
【检索策略】
├─ 语义相似度计算
├─ 混合检索:结合关键词匹配(BM25)+ 向量检索
└─ Top-K相似文本块召回
【输出】相关文本块列表 + 相似度分数3、融合与排序层(Fusion & Ranking)
目标:解决多源异构数据的合并、去重、优先级排序
3.1 异构数据对齐
【输入】图谱子图(结构化)+ 文本块(非结构化)
【处理】
├─ 实体对齐:识别文本块中提到的实体,与图谱实体关联
└─ 证据关联:将图谱中的关系映射回原始文档
【输出】对齐后的检索单元(实体-关系-文本证据)3.2 去重模块
【目标】消除信息冗余
├─ 实体级去重:同一实体在不同路径被重复检索
├─ 文本级去重:相似语义文本块
└─ 关系去重:同义关系合并3.3 重排序模块(Reranking)
【排序因子】
├─ 语义相似度(向量检索分数)
├─ 图结构重要性:
│ ├─ 节点度中心性(关联实体数量)
│ ├─ PageRank值(实体重要性)
│ └─ 路径长度(短路径优先)
├─ 时效性(时间衰减因子)
└─ 置信度(抽取模型置信分)
【输出】按综合得分排序的检索结果4、增强生成层(Augmented Generation)
目标:将检索结果转化为LLM可理解的上下文,生成高质量答案
4.1 上下文构建模块
【输入】排序后的检索结果
【处理】
├─ 图谱序列化:
│ ├─ 三元组转自然语言:("Elon Musk", "CEO of", "Tesla") → "Elon Musk是Tesla的CEO"
│ └─ 路径描述:将多跳路径转化为逻辑链
├─ 文本块摘要化:长文本压缩
└─ 指令注入:任务说明、输出格式约束
【输出】结构化Prompt4.2 答案生成模块
【输入】增强型Prompt
【处理】
├─ 事实性回答:基于检索结果直接回答
├─ 推理型回答:基于图谱路径进行逻辑推导
└─ 总结型回答:多源信息归纳
【输出】最终答案 + 可选的证据来源引用5、存储与基础设施层(Storage & Infrastructure)
三、优缺点分析
优点
1. 提升检索精准度
实体级检索比段落级检索更精准
减少语义漂移,避免向量检索的"近义词陷阱"
2. 具备推理能力
支持多跳推理:A→B→C
能回答需要逻辑链的问题,如"张三所在公司的竞争对手有哪些"
3. 可解释性强
检索结果以图谱形式呈现,推理路径可视化
用户可以看到答案是如何推导出来的
4. 解决长尾问题
低频但关键的实体能被精确检索
不被文本频率分布所影响
5. 知识复用性
图谱可跨文档、跨领域复用
减少重复抽取成本
缺点
1. 构建成本高
图谱构建需要大量LLM调用,成本高昂
大规模文档的实体关系抽取耗时且易出错
2. 维护复杂度高
图谱需要持续更新和维护
实体消歧、关系冲突需要人工干预
3. 查询延迟增加
图遍历查询通常比向量检索慢
多跳查询的响应时间显著增加
4. 覆盖完整性问题
抽取可能遗漏重要关系
非结构化信息在图谱化过程中丢失细节
5. 技术门槛高
需要同时掌握RAG、图谱数据库、NLP抽取
架构设计比传统RAG复杂得多
四、适用场景对比
五、实际应用建议
渐进式采用:从混合架构开始,核心文档建图谱,普通文档用向量
缓存优化:对高频图查询结果进行缓存
异步构建:图谱构建作为离线任务,不影响在线检索
结合向量:不要完全抛弃向量检索,两者互补
六、实际应用场景
GraphRAG不是替代传统RAG,而是在特定场景下的增强方案。对需要深度推理、实体关系复杂、对可解释性要求高的场景(如金融风控、医疗诊断、法律文书分析)价值巨大。
