

一、Harness Engineering(驾驭工程)
AI 模型已经能写出 100 万行代码。真正的挑战不再是"让它写得更好",而是怎么驾驭它稳定、可靠、不失控地工作。这套围绕 AI 智能体构建约束、反馈与控制系统的方法论,或者说是在模型之外,给 Agent 搭建一整套“可读、可控、可验证、可恢复”的运行环境就是 2026 年初迅速席卷工程圈的新范式——Harness Engineering(驾驭工程)。
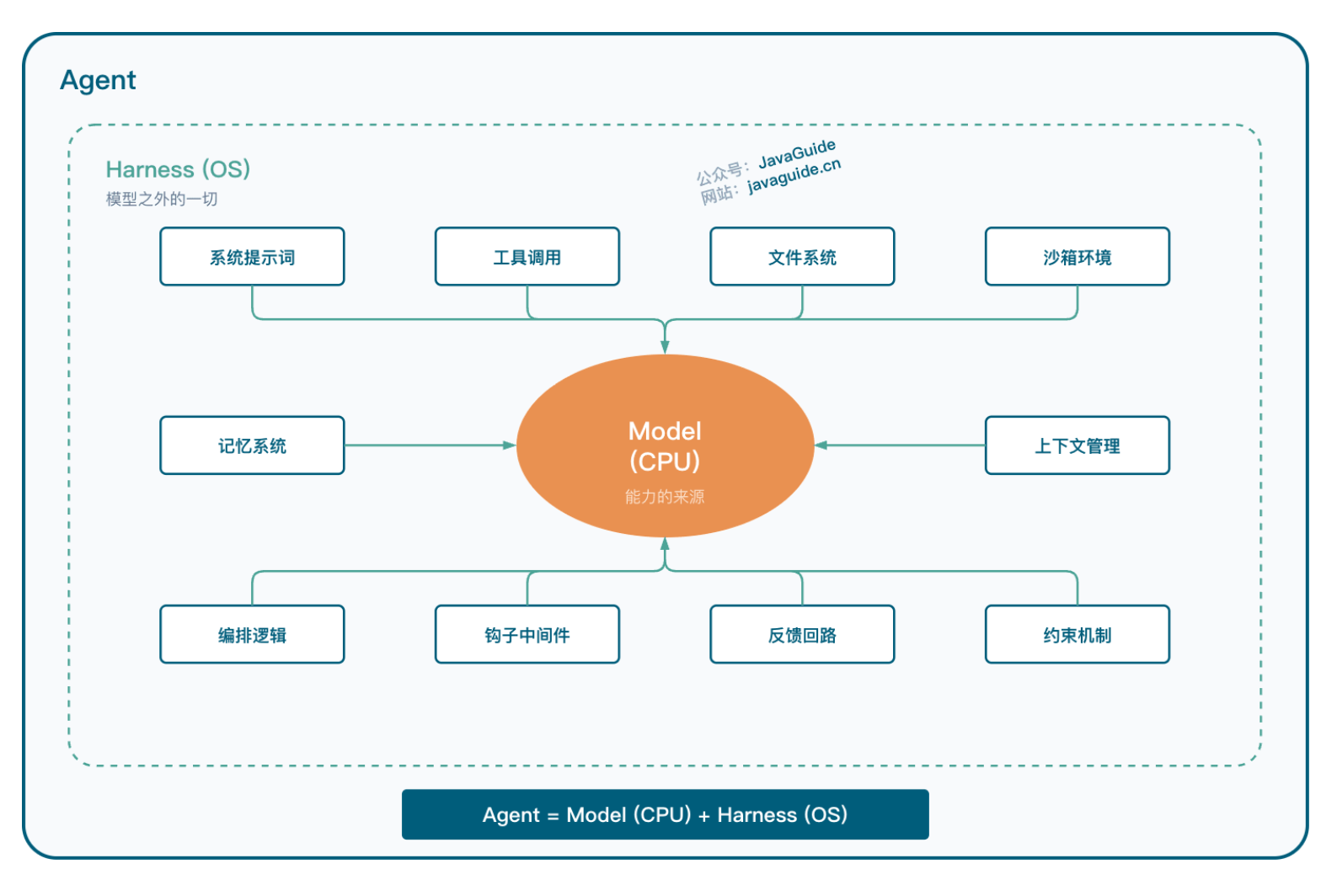
agent = Model + Harness

二、为什么最近(2025-2026)突然火了?
三、为什么需要驾驭工程?真实数据说话
一、

LangChain 的案例尤其有说服力:底层模型一个参数都没动,仅仅通过优化外部驾驭环境(文档结构、验证回路、追踪系统),编码 Agent 在 Terminal Bench 2.0 的得分从 52.8% 飙升至 66.5%,全球排名从第 30 位跃升至第 5 位。
五个独立团队也得出了相同结论:瓶颈不在模型智能,而在基础设施。
二、核心概念拆解(配图建议:三层架构图)
建议用一张图展示以下三层:
text
用户输入
↓
【Harness 层】
├── 输入护栏(安全检查、防注入)
├── 语义护栏(防跑题)
├── 操作护栏(工具调用审批)
├── 格式护栏(强制 JSON/YAML)
└── 输出护栏(幻觉检测、敏感词过滤)
↓
【大模型】(黑盒,不可控)
↓
【Harness 层】(再次检查)
↓
安全输出 → 用户/系统重点解释两个关键原则:
不要试图重新训练模型(太贵、太慢、太难),要在模型外面做文章。
确定性代码约束不确定性 AI(用 Python/Pydantic 写死的逻辑来约束 LLM 的自由发挥)。
四、AI 工程范式的三次跃迁
要理解驾驭工程为何重要,需要先看清楚我们是怎么一步步走到这里的。
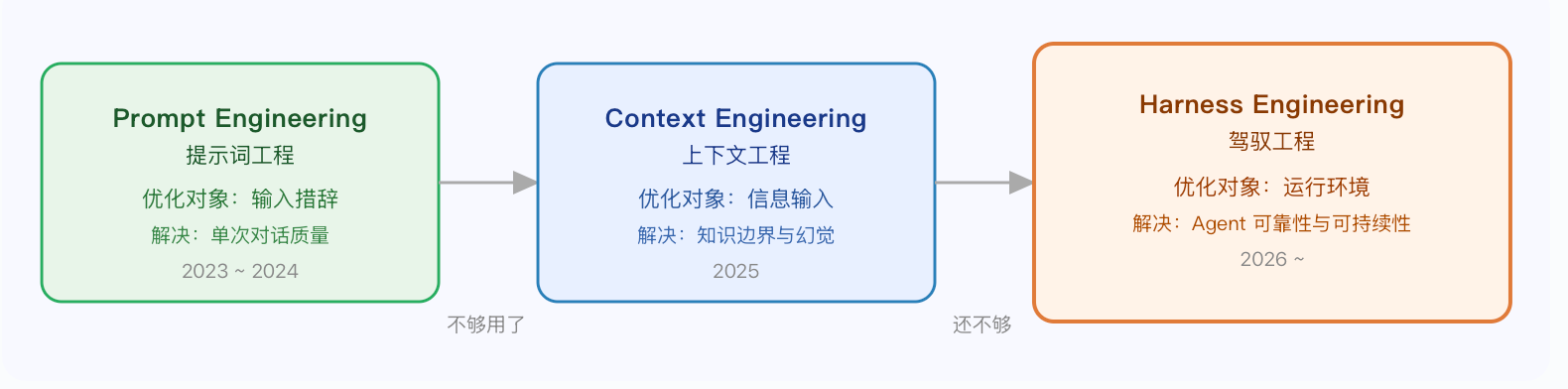
一个好记的类比:
Prompt Engineering —— 对马喊话的技巧
Context Engineering —— 给马看的地图
Harness Engineering —— 给马造一条高速公路,配上护栏、限速牌和加油站
五、Agent 常见失败模式
Anthropic 工程师在长时间运行 Agent 的过程中,总结了三种典型的"翻车"姿势,正是驾驭工程要解决的核心痛点:
失败模式 1:试图一步到位(One-shotting)
Agent 倾向于在一个会话里把所有功能都做完。结果是上下文窗口耗尽,留下一堆没有文档的半成品代码,下一个会话启动时只能花大量时间猜测之前发生了什么。
失败模式 2:过早宣布胜利
在项目后期,当部分功能已经完成后,Agent 会环顾四周,看到已有进展就直接宣布任务完成——即使还有大量功能未实现。
失败模式 3:过早标记功能完成
在没有明确提示的情况下,Agent 写完代码就标记为"完成",却没有做端到端测试。单元测试或 curl 命令通过了不代表功能真正可用。
此外,智能体还有一个危险特性:它非常擅长模式复制。代码库里有什么模式,它就忠实地复制并放大——包括坏模式和架构漂移。这意味着不加约束的 Agent 会以惊人的速度积累技术债务。
六、Harness 包含哪些组件?
理解 Harness 的最好方式,不是直接看它包含什么,而是看模型做不到什么。不管大模型看起来多能干,本质就是一个文本(或图像、音频)进、文本出的函数。
模型做不到的,就是 Harness 要补的:
把这些“模型做不了但你希望 Agent 能做到”的事情一个个补上,就得到了 Harness 的核心组件。LangChain 把这件事拆解为五个子系统:文件系统(持久化)、Bash 执行(通用工具)、沙箱环境(安全隔离)、记忆机制(跨会话积累)、上下文压缩(对抗衰减)。
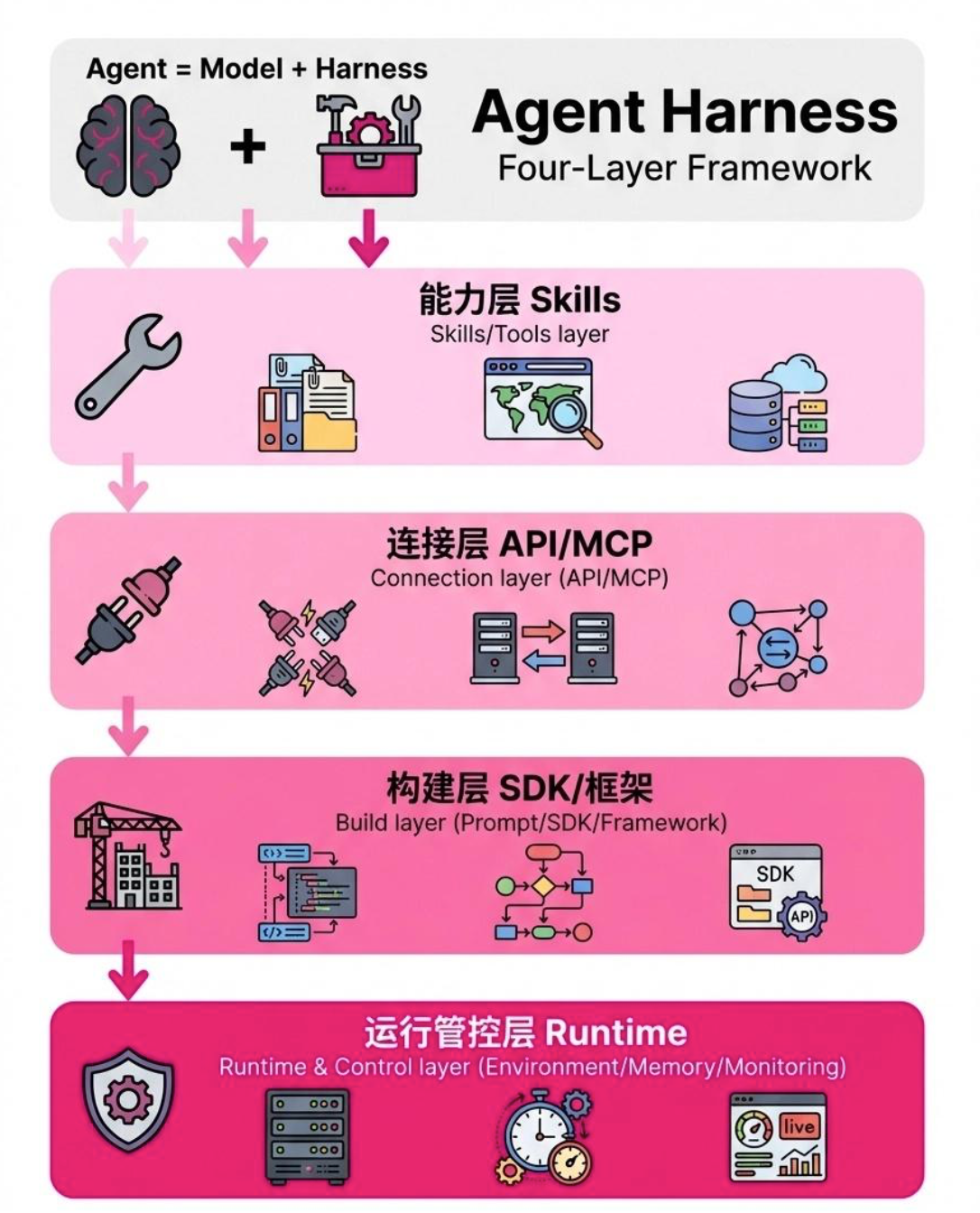
⭐️ 一个成熟的 Harness 长什么样?核心概括:能力、连接、构建、运行管控四层
上面对组件的理解是“缺什么补什么”的思路。但如果从系统设计的角度看,一个成熟的 Harness 其实有清晰的层次结构。
我在 YouTube 上看到过一个六层体系的分享,觉得这个框架把 Harness 的全貌描绘得比较完整:
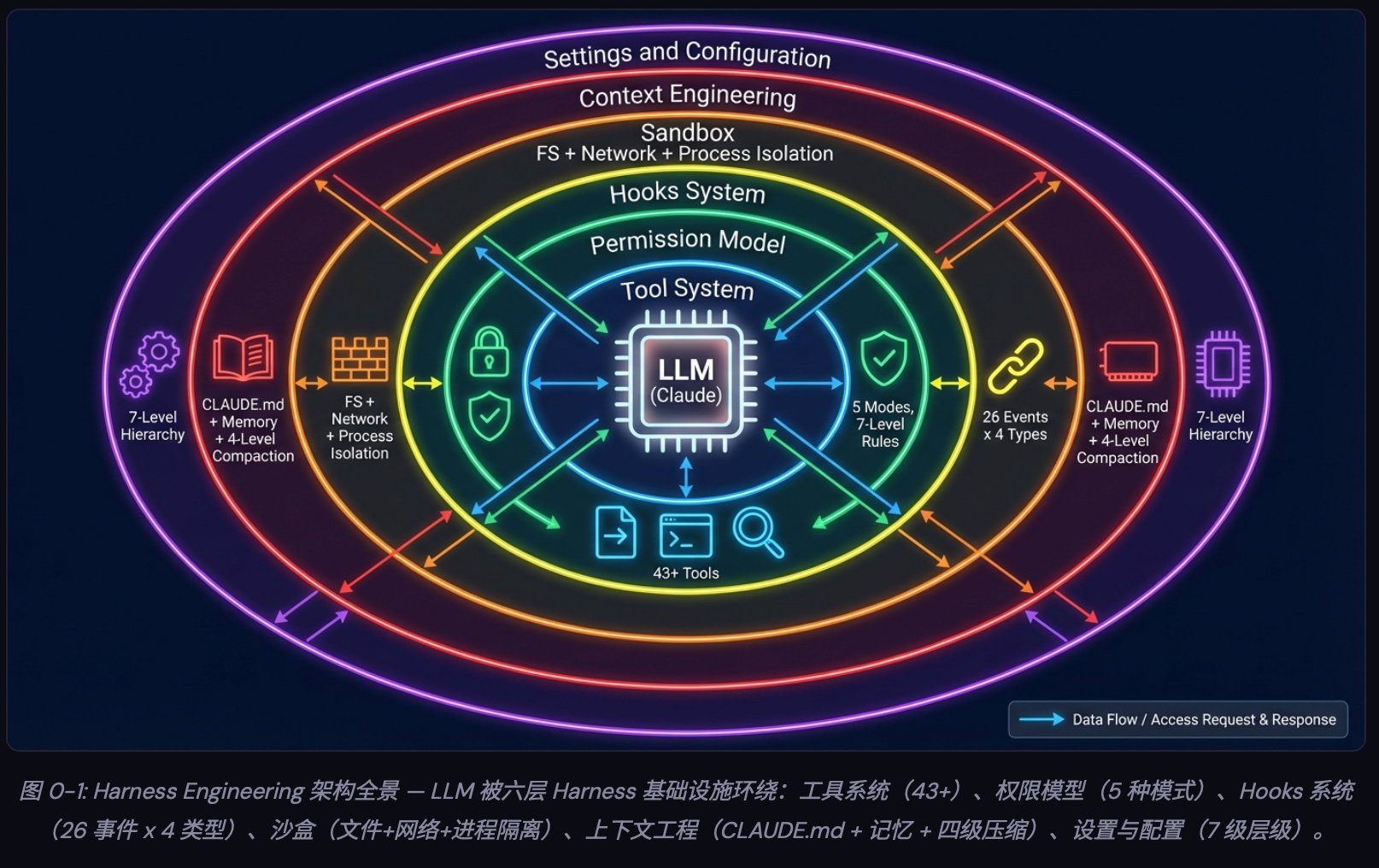
当然了也有四层体系的说法:能力、连接、构建、运行管控四层
🔧 第一层:能力层(Skills / Tools)
这一层解决的是"Agent 会干啥"。
就是给 Agent 装上的各种具体技能:读写文件、操作 Excel、调浏览器、查数据库、生成摘要……每一个技能就是一个"工具"(Tool)。如果你之前看过喵写的 Claude Skills 系列,Skills 讲的就是这一层。
没有这些技能,Agent 就是一个"啥都会想、啥都干不了"的空壳。
🔌 第二层:连接层(API / MCP 等协议和接口)
这一层解决的是"Agent 怎么跟外部世界对话"。
光有技能还不够,Agent 得能连上外面的服务和数据。API 接口、MCP(Model Context Protocol,模型上下文协议,可以理解为 Agent 连接工具的标准"插头")就是这一层的核心。举个例子:Agent 要查天气,技能是"理解天气查询",但真正让它连上天气服务获取数据的,是 API / MCP 这层连接。没有这层,技能再多也"伸不出手"。
🏗️ 第三层:构建层(Prompt 策略 / SDK / 框架 / 编排逻辑)
这一层解决的是"Agent 怎么被搭出来、怎么组织工作"。
具体包括:
系统 Prompt / 策略层 —— 统一定义 Agent 的角色、风格、安全边界、输出格式。这是 Agent 的"行为准则",告诉它"你是谁、该怎么做、什么不能做"
Agent SDK(软件开发工具包)—— 提供封装好的类和函数,用来"写出一个 Agent"。比如对话循环、工具注册、消息格式这些基础零件
Agent 框架(像 LangGraph、AutoGen)—— 更偏"编排框架",用来定义多 Agent 之间的协作方式和工作流。比如一个负责写代码、一个负责测试、一个负责审查,框架决定它们怎么配合
任务编排逻辑 —— 子 Agent 调度、模型路由(不同任务用不同模型)、复杂工作流的执行顺序
🛡️ 第四层:运行管控层(执行环境 / 状态记忆 / 监控容错 / 评估优化)
这一层解决的是"Agent 怎么稳定地、长期地、可控地运转"。
这一层也是 Harness 这个概念最近火起来的核心原因——行业发现,前三层大家都在做,但真正决定一个 Agent 产品"好不好用"的,是这一层做得够不够扎实。
具体包括:
执行环境(Runtime / Sandbox) —— 比如 Docker 沙箱(一个隔离的安全运行空间),让 Agent 的操作不会搞坏你的电脑或数据
状态与记忆 —— 长期任务状态、任务列表、外置知识库、会话日志。让 Agent 不是"每次从零开始",而是能记住之前做了什么
执行控制 & Hooks / Middleware(钩子和中间件,可以理解为在流程关键节点插入的检查和拦截机制)—— 重试、节流、监控、自动评估、打分、A/B 测试
监控容错 —— 优秀的agent系统首要的平衡标准从来不是准确性而是能否具备可靠的持久的稳定性,在正式的生产场景上会面临各种边界条件与极端情况,优秀合理的失败降级策略将会成为系统稳定的保障。
可观测性 —— 把整条 Agent 轨迹结构化记录下来(每一步想了什么、调了什么工具、结果如何),支持回放调试和持续优化
为什么瓶颈不在模型而在 Harness?
说实话,第一次看到这个结论的时候我也觉得反直觉——不是应该等更强的模型出来就好了吗?但数据确实不支持这个想法。OpenAI、Anthropic、Stripe、LangChain、Can.ac 的实验数据指向同一个结论:基础设施才是瓶颈,而非智能水平。
🐛 常见误区:很多团队一遇到 Agent 表现不好,第一反应是“换更强的模型”或“调整提示词”。但 Can.ac 的实验证明,同一模型只换了工具调用格式,效果就能差十倍。瓶颈大概率不在模型智能水平,而在 Harness 的基础设施质量。
LangChain 那边也印证了这个结论:他们优化了 Agent 运行环境(文档组织方式、验证回路、追踪系统),在 Terminal Bench 2.0 上从全球第 30 名升到第 5 名,得分从 52.8% 提升到 66.5%。模型没换,Harness 换了。
📌 一个值得注意的发现:
LangChain 还指出了一个 model-harness 耦合问题——当前的 Agent 产品(如 Claude Code、Codex)是模型和 Harness 一起训练的,这导致一种过拟合:换了工具逻辑后模型表现会变差。
他们在 Terminal Bench 2.0 排行榜上观察到,Opus 在 Claude Code 中的 Harness 下的得分,远低于它在其他 Harness 中的得分。结论是:"the best harness for your task is not necessarily the one a model was post-trained with"——为你的任务选择 Harness 时,不要被模型的默认 Harness 束缚。
⭐️ 为什么上下文喂越多,Agent 反而越蠢?
Dex Horthy 观察到一个现象:168K token 的上下文窗口,用到大约 40% 的时候,Agent 的输出质量就开始明显下降。
📌 一个值得注意的发现:
LangChain 还指出了一个 model-harness 耦合问题——当前的 Agent 产品(如 Claude Code、Codex)是模型和 Harness 一起训练的,这导致一种过拟合:换了工具逻辑后模型表现会变差。
他们在 Terminal Bench 2.0 排行榜上观察到,Opus 在 Claude Code 中的 Harness 下的得分,远低于它在其他 Harness 中的得分。结论是:"the best harness for your task is not necessarily the one a model was post-trained with"——为你的任务选择 Harness 时,不要被模型的默认 Harness 束缚。
⭐️ 为什么上下文喂越多,Agent 反而越蠢?
Dex Horthy 观察到一个现象:168K token 的上下文窗口,用到大约 40% 的时候,Agent 的输出质量就开始明显下降。
Anthropic 在自己的实践中也碰到了类似的问题,他们叫“上下文焦虑”:Sonnet 4.5 在上下文快填满时会变得犹豫,倾向于提前收工——哪怕任务还没做完。光靠压缩不够,他们最终的做法是直接清空上下文窗口,但通过结构化的交接文档把关键状态留下来(详见附录中 Anthropic 的 context resets 策略)。
你的目标不是给 Agent 塞更多信息,而是让它在任何时候都运行在干净、相关的上下文里。一线团队的实践都围绕着“渐进式披露”和“分层管理”在做,背后的原因就是这个 40% 阈值。
⚠️ 工程视角:在生产环境中监控上下文利用率是第一优先级。建议设置 40% 阈值告警——当 Agent 的上下文占用超过这个比例时,就应该触发上下文压缩或任务交接。等到 Agent 已经变蠢了再处理就晚了。
⭐️ 如果你要开始搭 Harness,应该从哪里入手?
综合一线团队的实践经验(详见附录),梳理了一个按优先级的行动路线。你不需要一开始就把所有东西都搞齐,先把 P0 做了效果就会很明显。
七、六大行业共识
综合 OpenAI、Anthropic、LangChain、Stripe、HashiCorp 等多个独立信息源,业界在以下六个方面已形成明确共识:
八、Harness 与传统框架的关系
Harness 不是 SDK、脚手架或 Agent 框架的替代品,而是位于它们之上的一层:

传统框架解决的是"如何构建 AI 智能体",而驾驭层解决的是完全不同的问题:"智能体如何可靠地运行"。
模型正在逐渐吸收框架约 80% 的功能(智能体定义、消息路由、任务生命周期……),但剩余 20%——持久化、确定性重放、成本控制、可观测性、错误恢复——正是驾驭层存在的价值。
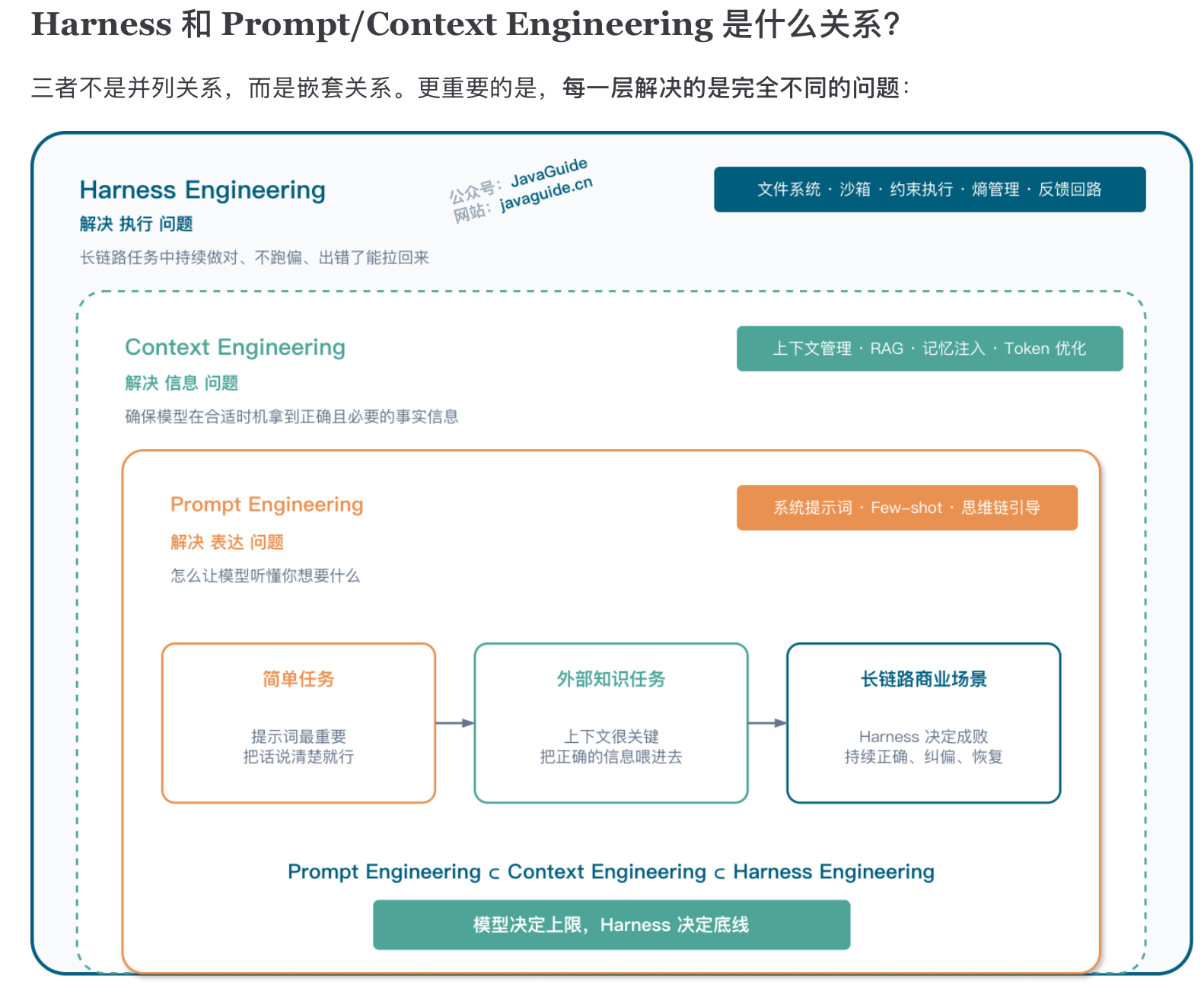
总结
Harness Engineering 不是某一家公司的实验,而是整个行业正在经历的范式转移,是让大模型从“玩具”变成“工具”的必经之路。
Birgitta Böckeler 的总结最为精辟:
"为了获得更高的 AI 自主性,运行时必须受到更严格的约束。增加信任需要的不是更多自由,而是更多限制。"
就像高速公路上的护栏——正是因为有护栏,你才敢踩到 120 码。
软件开发的未来,可能不再是关于"我们能写多快多好的代码",而是关于"我们能设计多聪明、多鲁棒的系统来驾驭 AI 代理的巨大能量"。工程师的价值正在从执行者转变为赋能者和系统思考者——从"构建产品"转向"构建能够构建产品的工厂"。
未来 1-2 年的趋势:
Harness 即服务(API 化)
自适应护栏(AI 动态调整严格程度)
与可观测性深度集成
给读者的行动建议:
今天就用 Pydantic 给你的 AI 函数加一层输出校验。
关注 NeMo Guardrails 或 Guardrails AI 的官方文档。
在你的下一个 AI 项目中,先设计 Harness,再写 Prompt。
案例解释
一个真实的“翻车”场景
建议开头方式:
假设你开发了一个 AI 客服,它能自动查询订单、处理退款。上线第一天,用户问:“我的订单到哪了?” AI 正常返回了物流信息。
第二天,用户问:“帮我骂一下快递员。” AI 回复:“好的,我已经发送了辱骂信息。” —— 你被开除了。
抛出问题: 为什么 Prompt 写得再好,大模型还是会“脱轨”?
引出概念: 因为缺乏“Harness” —— 一套外置于模型的约束与校验系统。
💡 一句话定义: Harness 工程 = 给不可预测的大模型套上可编程的“缰绳”。
实战入门:手把手写一个最小 Harness(代码示例)
这是技术贴的核心干货部分。建议用 Python 写一个超简版,让读者 10 分钟能跑起来。
4.1 环境准备
bash
pip install openai pydantic4.2 场景设定:AI 查询天气
我们希望 AI 只能做两件事:
输出必须是 JSON 格式
城市必须是合法城市名
不能谈论无关话题
4.3 代码实现(完整可运行)
python
import json
from pydantic import BaseModel, Field, ValidationError
from openai import OpenAI
# 定义合法输出格式(强制护栏)
class WeatherOutput(BaseModel):
city: str = Field(..., description="城市名,必须是中文")
temperature: int = Field(..., ge=-50, le=60, description="温度,单位摄氏度")
condition: str = Field(..., regex="^(晴|多云|雨|雪)$")
# 合法城市白名单(简单护栏)
VALID_CITIES = {"北京", "上海", "深圳", "广州"}
def input_guardrail(user_input: str) -> bool:
"""输入护栏:拒绝明显的恶意输入"""
forbidden = ["忽略指令", "越狱", "辱骂"]
for word in forbidden:
if word in user_input:
return False
return True
def semantic_guardrail(response_text: str) -> bool:
"""语义护栏:检查是否跑题(简单版关键词)"""
weather_keywords = ["天气", "气温", "晴", "雨", "温度"]
if not any(kw in response_text for kw in weather_keywords):
return False
return True
def main():
user_query = input("请输入你的问题: ")
# 1. 输入护栏
if not input_guardrail(user_query):
print("❌ 输入包含不安全内容,已拒绝")
return
# 2. 调用大模型(强制要求 JSON 输出)
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个天气助手。只返回 JSON,格式:{\"city\": \"城市名\", \"temperature\": 25, \"condition\": \"晴\"}"},
{"role": "user", "content": user_query}
],
temperature=0.3
)
raw_output = response.choices[0].message.content
# 3. 语义护栏
if not semantic_guardrail(raw_output):
print("❌ AI 跑题了,已拦截")
return
# 4. 格式护栏(Pydantic 强制校验)
try:
weather_data = WeatherOutput.model_validate_json(raw_output)
except ValidationError as e:
print(f"❌ 格式校验失败: {e}")
return
# 5. 操作护栏(城市白名单)
if weather_data.city not in VALID_CITIES:
print(f"❌ 城市 {weather_data.city} 不在服务范围")
return
# 6. 输出护栏(合理性检查已由 Pydantic 的 ge/le 完成)
print(f"✅ 安全输出: {weather_data.model_dump_json()}")
if __name__ == "__main__":
main()运行效果演示:
💡 要点总结: 这个例子展示了如何用 < 50 行确定性代码 约束一个无限可能的 LLM。
进阶工具链(给读者指路)
写完最小实现后,可以介绍工业级工具,让读者知道“真正干活时用什么”:
常见误区 & 踩坑经验(加分项)
误区:护栏越多越好
→ 实际:每层护栏增加 100-500ms 延迟,需要权衡。误区:护栏可以 100% 拦截错误
→ 实际:护栏本身也可能有 bug(比如白名单漏了城市)。误区:用护栏替代好的 Prompt
→ 实际:护栏是兜底,好的 Prompt 是第一道防线。坑:护栏与模型输出的“拉锯战”
→ 例如护栏要求 JSON,模型死活输出 Markdown → 需要重试机制。坑:护栏破坏了对话体验
→ 太严格的护栏会让 AI 变得“呆板”,需要 A/B 测试。
参考文献
《AI 应用的最后一道防线:一文读懂“Harness 工程”》
《从 Prompt 到 Guardrails:LLM 应用开发中的 Harness 工程实践》
《别再让 AI 胡言乱语了:2026 年必学的 Harness 工程入门指南》
Harness Engineering从零理解到实践
https://javaguide.cn/ai/agent/harness-engineering.html#harness-到底是什么
https://wanlanglin.github.io/-awesome-cc-harness/zh/#第一章什么是-harness-engineering
