

一、数据清洗与处理工具分类概览
文档处理工具体系
├── 📄 通用解析器(多格式支持)
├── 📊 PDF专用工具
├── 📝 Office文档工具
├── 🌐 网页与HTML工具
├── 💻 代码与结构化数据
├── 🎓 学术文献专用
├── 🖼️ 多模态与OCR工具
└── 🔧 预处理与清洗工具
二、核心工具对比表格
1. 通用解析器(一站式解决方案)
工具 | 特点 | 支持格式 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
自动格式检测,统一API | 30+格式:PDF、Word、Excel、PPT、Email、HTML、图片等 | ✅ 一站式解决方案 | ❌ 依赖第三方服务 | 混合格式文档库 | v0.10+ | |
LangChain | 标准化接口,易于集成 | 文本、CSV、JSON、Markdown、PDF、HTML | ✅ 与RAG框架深度集成 | ❌ 功能相对基础 | LangChain项目 | v0.1+ |
2. PDF处理工具(专用优化)
工具 | 特点 | 核心能力 | 优点 | 缺点 | 适用文档类型 | 最新版本 |
|---|---|---|---|---|---|---|
PyMuPDF (fitz) | 底层C++实现,高性能 | 文本提取、图像提取、元数据、页面操作 | ✅ 处理速度最快 | ❌ API较底层 | 大型PDF文档 | v1.23+ |
pdfplumber | 专注于布局分析 | 表格提取、文本布局保持、可视化调试 | ✅ 表格提取精度高 | ❌ 处理速度中等 | 表格密集型PDF | v0.10+ |
pypdf (原PyPDF2) | 轻量级基础库 | 基础文本提取、合并分割、加密解密 | ✅ 纯Python实现 | ❌ 功能有限 | 简单文本PDF | v4.0+ |
Camelot | 高级表格提取专家 | 基于图像和文本的表格检测 | ✅ 表格提取准确率高 | ❌ 仅限表格提取 | 财务报表 | v0.11+ |
3. Office文档处理
工具 | 特点 | 支持格式 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
python-docx | 专业Word处理 | .docx | ✅ 完整的Word操作 | ❌ 仅支持docx | Word文档处理 | v0.8.11+ |
pandas | Excel数据处理专家 | .xlsx, .xls, .csv | ✅ 强大的数据分析 | ❌ 格式信息丢失 | 数据报表分析 | v2.0+ |
openpyxl | Excel格式保持 | .xlsx | ✅ 完整格式支持 | ❌ 仅支持xlsx | 需要格式保留的Excel处理 | v3.1+ |
4. 网页与HTML处理
工具 | 特点 | 核心能力 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
BeautifulSoup4 | HTML解析标准库 | HTML/XML解析、DOM遍历、数据提取 | ✅ 解析能力强 | ❌ 需要搭配下载器 | 网页数据抓取 | v4.12+ |
Readability | 文章内容提取 | 去除广告导航、提取正文 | ✅ 专注文章提取 | ❌ 仅限文章类网页 | 新闻博客抓取 | 0.8+ |
Trafilatura | 现代网页提取器 | 正文提取、元数据获取、多语言 | ✅ 专门为NLP优化 | ❌ 相对较新 | 大规模网页抓取 | v1.6+ |
5. 代码与结构化数据
工具 | 特点 | 支持语言 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
tree-sitter | 语法树解析 | Python、JS、Java、Go等20+语言 | ✅ 增量解析 | ❌ 需要编译 | 代码分析 | v0.20+ |
pygments | 语法高亮分词 | 500+语言 | ✅ 支持语言极多 | ❌ 仅限分词高亮 | 代码展示 | v2.15+ |
jq (Python绑定) | JSON处理专家 | JSON | ✅ JSONPath支持 | ❌ 学习曲线陡 | 大规模JSON处理 | 1.6+ |
6. 学术文献专用
工具 | 特点 | 核心功能 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
GROBID | 学术PDF解析 | 参考文献提取、元数据、章节识别 | ✅ 学术专用优化 | ❌ 需要Java环境 | 学术论文处理 | v0.7+ |
ScienceParse | 论文PDF解析 | 标题作者提取、摘要、章节 | ✅ 深度学习模型 | ❌ 需要运行服务 | 论文管理 | v2+ |
PDFFigures 2.0 | 图表提取 | 图表检测、标题关联、图像提取 | ✅ 图表识别准确 | ❌ 仅限图表提取 | 论文图表提取 | 2.0+ |
7. 多模态与OCR工具
工具 | 特点 | 核心能力 | 优点 | 缺点 | 适用场景 | 最新版本 |
|---|---|---|---|---|---|---|
Tesseract | 开源OCR标准 | 多语言OCR、版面分析、训练自定义 | ✅ 开源免费 | ❌ 准确率中等 | 通用OCR任务 | v5.3+ |
PaddleOCR | 中文OCR专家 | 中文优化、表格识别、方向检测 | ✅ 中文识别优秀 | ❌ 其他语言一般 | 中文文档处理 | v2.6+ |
EasyOCR | 即用型OCR | 80+语言、GPU加速、简单API | ✅ 开箱即用 | ❌ 模型较大 | 快速原型 | v1.6+ |
Donut | 文档理解模型 | 端到端文档理解、文档问答、无OCR | ✅ 无需OCR预处理 | ❌ 需要GPU | 智能文档分析 | 2023+ |
Layout-parser | 文档布局分析 | 版面检测、元素分类、OCR集成 | ✅ 布局分析专业 | ❌ 依赖深度学习 | 复杂版面文档 | v0.3+ |
8. 最新突破性工具
工具 | 类型 | 核心创新 | 适用场景 | 特点 | 状态 |
|---|---|---|---|---|---|
MinerU | 通用文档理解 | 统一文档理解框架,支持多格式多任务 | 企业文档智能处理、知识图谱构建 | 🆕 多任务统一模型 | 2024新发布,研究阶段 |
olmOCR | 专门化OCR | 针对扫描文档优化的OCR引擎 | 历史档案数字化、老旧扫描件处理 | 🆕 旧文档优化 | 2024推出,专业领域 |
DocLLM | 大语言模型文档理解 | 专门为文档设计的LLM,理解表格图表 | 复杂文档问答、文档推理 | 🆕 理解文档结构 | 2024研究热点 |
9. 预处理与清洗工具
工具 | 类型 | 主要功能 | 优点 | 缺点 | 适用阶段 |
|---|---|---|---|---|---|
clean-text | 文本清洗 | 标准化、去噪、规范化 | ✅ 专门为NLP优化 | ❌ 功能相对基础 | 预处理阶段 |
ftfy | 编码修复 | 修复乱码、Unicode问题 | ✅ 编码问题专家 | ❌ 仅限编码问题 | 数据清洗阶段 |
NLTK/spaCy | NLP预处理 | 分词、词干化、实体识别 | ✅ 完整的NLP流水线 | ❌ 学习曲线陡 | 深度文本处理 |
三、工具选择决策树
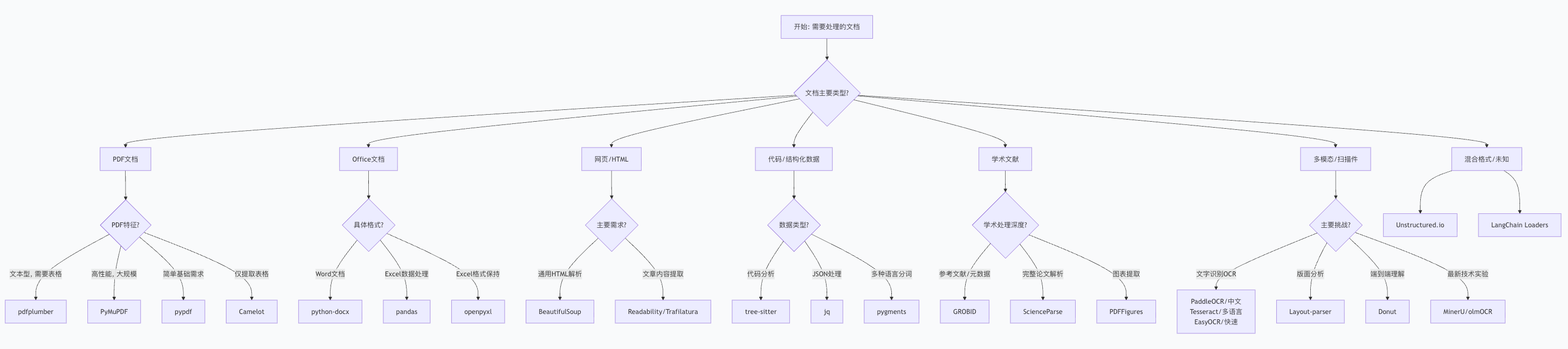
四、最佳实践建议
1. 按场景选择策略
业务场景 | 推荐工具组合 | 理由 |
|---|---|---|
企业知识库 | Unstructured + pdfplumber + python-docx | 全面覆盖,质量稳定 |
学术研究 | GROBID + ScienceParse + PaddleOCR | 学术专用,参考文献强 |
金融报表 | Camelot + pandas + openpyxl | 表格处理,数据分析 |
多语言内容 | Tesseract + Trafilatura + ftfy | 多语言支持,编码处理 |
快速原型 | LangChain + EasyOCR + BeautifulSoup | 快速上手,生态完善 |
高性能生产 | PyMuPDF + jq + 定制清洗 | 性能优先,可定制 |
