

一、介绍:大模型应用策略体系
├── 推理策略
│ ├── 链式思考 (CoT)
│ └── ReAct(包含工具调用决策) ← 你的直觉部分正确
│
├── 工具调用策略
│ └── Function Calling(具体实现标准) ← 这是明确的工具调用策略
│
├── 优化策略
│ └── Reflection(自我改进策略) ← 这是质量策略
│
└── 规划策略
├── ToT(思维树)
└── GoT(思维图)
二、Function Calling(函数调用)、ReAct(Reasoning + Acting)、Reflection(反思)介绍
1、Function Calling(函数调用)
概念
Function Calling 是大模型与外部工具、API 和服务交互的标准方式,使 LLM 能够执行具体操作而不仅仅是生成文本。
核心机制
函数描述:提供函数名、参数(类型、描述)和用途的清晰说明
意图识别:模型分析用户请求,判断是否需要调用函数
参数提取:从自然语言中提取结构化参数
执行调用:系统执行实际函数调用
结果整合:将执行结果融入模型回复
# 示例:OpenAI Function Calling格式
functions = [
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "城市名称"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
}
}
}
]2、ReAct(Reasoning + Acting)
概念
ReAct 是一种结合推理(Reasoning)和行动(Acting)的框架,模仿人类“思考-行动-观察”的循环过程。
核心流程
思考 → 行动 → 观察 → 思考 → ...
关键技术组件
2.1. 推理(Reasoning)
分析当前情况
确定需要的信息
规划下一步行动
2.2. 行动(Acting)
选择适当的工具/动作
执行具体操作
包括Function Calling
2.3. 观察(Observation)
接收行动结果
更新上下文理解
2.4工作模式示例
用户:北京的人口是多少?比上海多吗?
ReAct循环:
1. 思考:需要获取北京和上海的人口数据
2. 行动:调用get_population("北京")
3. 观察:北京人口2189万
4. 思考:现在需要上海人口数据
5. 行动:调用get_population("上海")
6. 观察:上海人口2487万
7. 思考:上海人口更多,计算差异
8. 回答:上海人口更多,多出约298万人
class ReActAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = tools
self.memory = []
def step(self, observation):
# 结合历史生成思考
thought = self.llm.generate_reasoning(observation, self.memory)
# 决定行动
action = self.llm.decide_action(thought, self.tools)
if action['type'] == 'tool_call':
# 执行工具调用
result = self.execute_tool(action)
self.memory.append(('action', action, result))
return result
elif action['type'] == 'answer':
return action['content']3. Reflection(反思)
核心机制
1. 生成阶段
模型产生初始回答
包含推理过程
2. 反思阶段
批判性评估自身回答
识别问题:事实错误、逻辑漏洞、不完整等
提出改进建议
3. 修正阶段
基于反思结果重新生成
整合改进意见
反思类型
自我反思
# 示例反思提示
reflection_prompt = """
请批判性评估以下回答:
1. 事实准确性如何?
2. 逻辑是否严密?
3. 是否完整回答了问题?
4. 有哪些可以改进的地方?
原始回答:{original_answer}
"""多角度反思
事实核查反思
逻辑一致性反思
完整性反思
伦理安全性反思
实现模式
单次反思
输入 → 生成回答 → 反思 → 修正回答 → 输出
迭代反思
输入 → 生成 → 反思1 → 修正1 → 反思2 → 修正2 → ... → 输出
多模型反思
主模型生成
批评模型评估
修正模型改进
class ReflectionAgent:
def __init__(self, generator, critic):
self.generator = generator # 生成模型
self.critic = critic # 批判模型
def reflect_and_refine(self, question, max_iterations=3):
answer = self.generator(question)
for i in range(max_iterations):
# 反思
critique = self.critic(question, answer)
if critique['needs_improvement']:
# 基于反思重新生成
refinement_prompt = f"""
原始回答:{answer}
批评意见:{critique['feedback']}
请改进回答:
"""
answer = self.generator(refinement_prompt)
else:
break
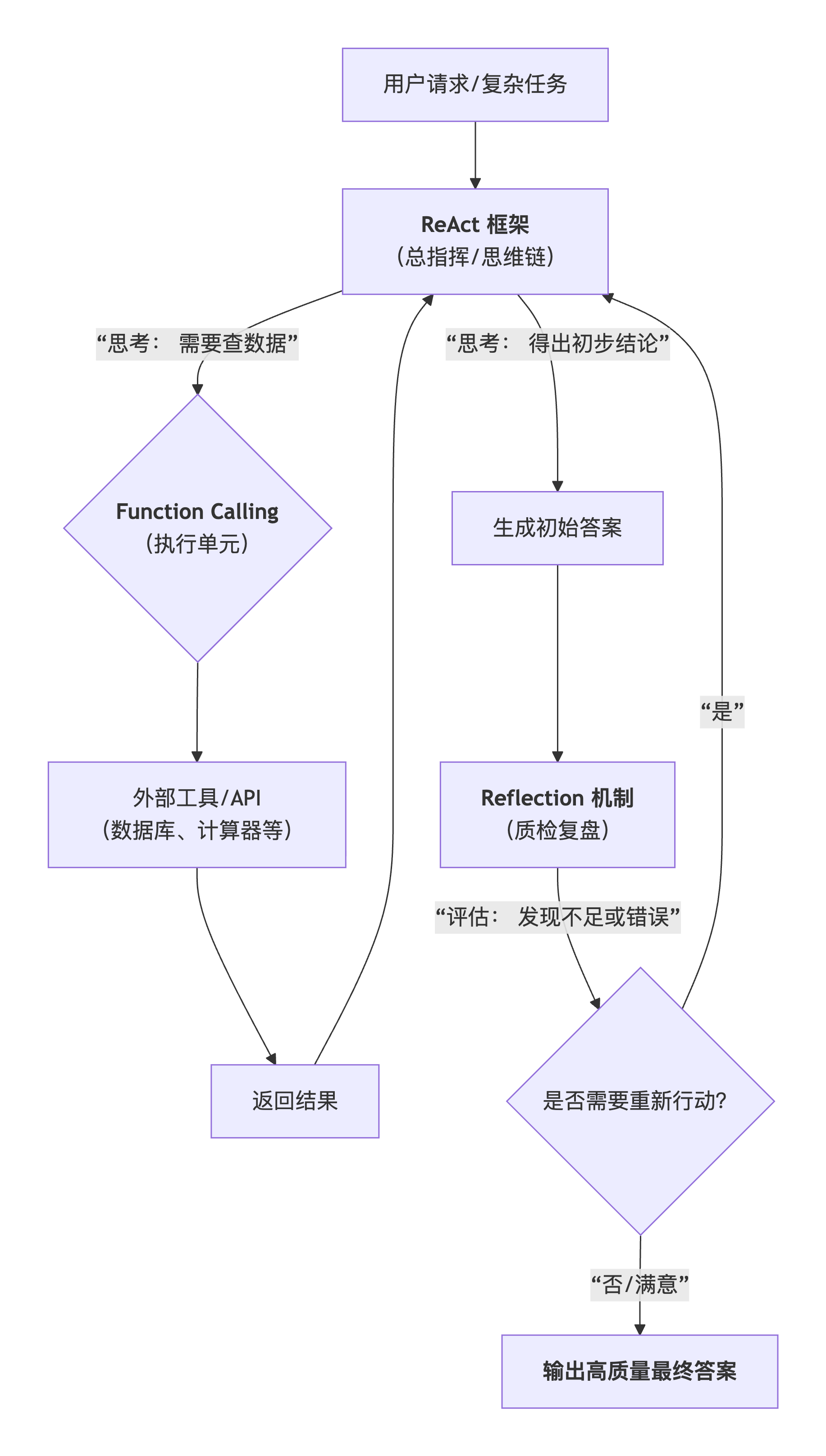
return answer三者的关系与整合
用户问题
↓
ReAct框架启动
├── 思考:分析问题需求
├── 行动:通过Function Calling获取信息
├── 观察:接收工具返回结果
└── 整合:生成初步答案
↓
Reflection启动
├── 自我评估:检查准确性、完整性
├── 识别不足:发现遗漏或错误
└── 触发修正:可能需要额外Function Calling
↓
最终优化答案
完整架构示例
class IntelligentAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = tools
self.react = ReActModule(llm, tools)
self.reflector = ReflectionModule(llm)
def process(self, query, max_react_steps=5, max_reflections=2):
# ReAct循环
context = {"query": query}
for step in range(max_react_steps):
# 推理和行动
thought, action = self.react.think_and_act(context)
if action["type"] == "final_answer":
# 进入反思阶段
for ref in range(max_reflections):
improved = self.reflector.reflect_and_improve(
query,
action["answer"]
)
if improved["satisfactory"]:
return improved["answer"]
return action["answer"]
# 执行工具调用
result = self.execute_function(action)
context.update(result)Function Calling、ReAct、Reflection 对比总结表
技术特性对比
定位总结表
架构角色对比
三者的协同关系与演进视图
应用场景对比
组合使用场景
选择指南
更精准的分类
1. Function Calling → 纯粹的“工具调用策略”
定位:工具调用的执行层规范
核心问题:“工具调用这件事,应该用什么格式、什么标准来做?”
类比:HTTP协议之于网络通信——定义了通信的格式和规则
2. ReAct → “推理与行动策略”
包含:工具调用策略 + 推理策略 + 状态管理策略
核心问题:“面对复杂问题,应该如何思考、何时行动、如何决策?”
工具调用在ReAct中:只是Action的一种具体实现方式
类比:项目管理方法论——包含任务分配(工具调用)、进度跟踪、决策调整
3. Reflection → “质量改进策略”
可能涉及工具调用:但只是作为验证手段
核心问题:“如何评估和改进已有的输出/决策?”
类比:软件测试和质量审查流程——可能发现bug需要修复(调用工具验证)
