

一、Skills 是什么:从概念来源到运作原理
2025 年 10 月中旬,Anthropic 正式发布 Claude Skills。
两个月后,Agent Skills 作为开放标准被进一步发布,意在引导一个新的 AI Agent 开发生态。
Agent Skills 就像一份“带目录的说明书”当然为了更好的理解,你可以把 Skills 理解为“通用 Agent 的扩展包” 。更专业地说,它是一种渐进式披露的提示词管理机制。
换句话来说Agent Skills 本质上是一个模块化的 Markdown 文件,能教会 AI 工具 (如 Claude、GitHub Copilot、Cursor 等) 执行特定任务,且支持自动触发、团队共享与工程化管理,彻底告别重复的提示词输入。
由于Agent 可通过加载不同的 Skills 包,使其来具备不同的专业知识、工具使用能力,能够稳定完成特定任务。
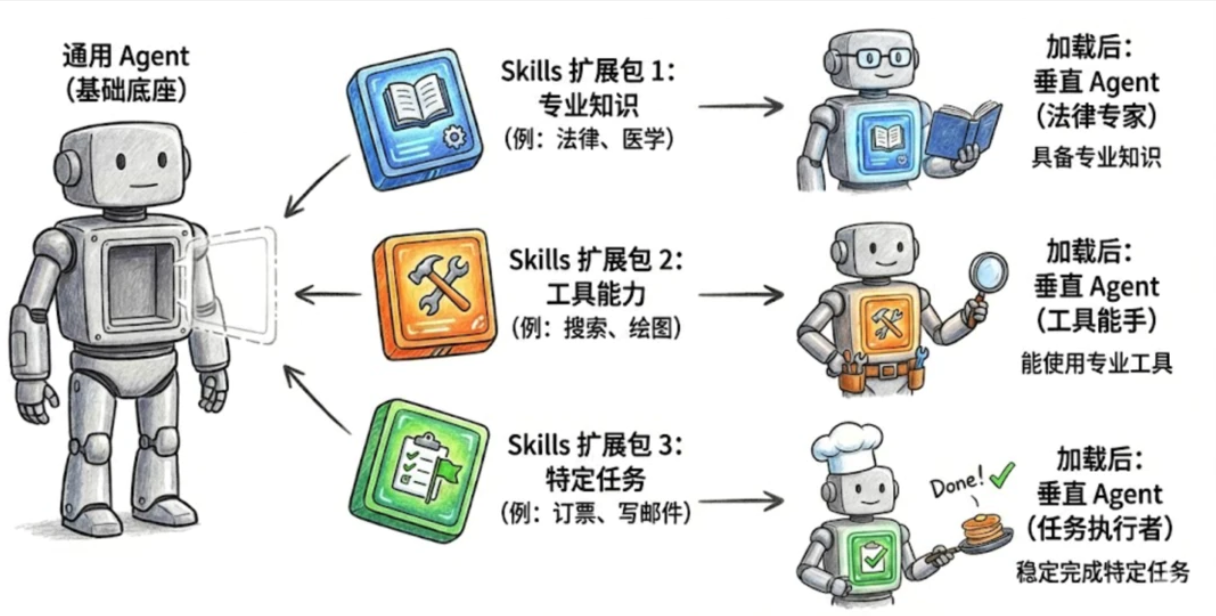
普遍直接认为是:行为规范 + 专业知识 + 使用时机的组合
二、Agent Skills的基本结构

按照Skills的渐进式披露机制分为三个层次:
元数据(Metadata)
指令(Instruction)
资源(Resource)
其中,只有元数据层默认被加载到大模型的上下文中,其余两层均为按需加载。大家可以这样理解:
层级 1:技能发现 -- AI 先读取所有技能的元数据(包含必要的name 和 description。如同书的目录,告诉模型有哪些可用的能力),判断任务是否相关,这些元数据始终在系统提示中。
层级 2:加载核心指令(如同书的正文,详细说明在某一能力下如何执行某项任务;) -- 如果相关,AI 自动读取 SKILL.md 的正文内容,获取详细指导。
层级 3:加载资源文件(如同书的附录,提要时读取额外文件(如脚本、示例),或通过工具执行脚本。
智能体在执行时,首先仅载入“目录”(元数据),随后根据实际需求,再决定是否查阅该目录下的“正文”(指令)与“附录”(资源)。
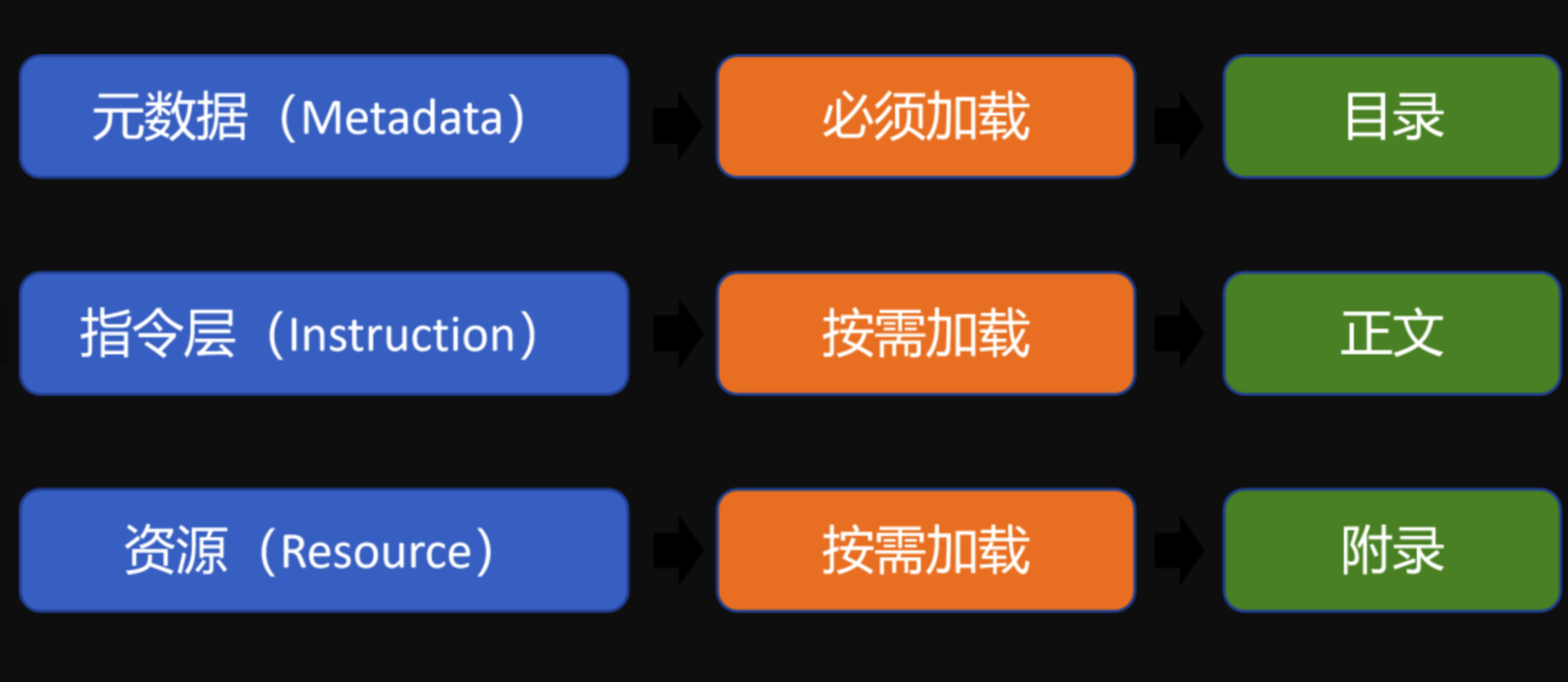
执行原理
意图识别,决定是否进入受控执行路径。
命中 Skill 后,系统加载 SKILL.md,建立工具权限与行为边界,再结合上下文进行推理。
只有在确实需要时才调用被允许的外部工具,否则在规则内完成逻辑。
最终结果经过约束整合后输出,用户的下一次输入触发新一轮完整流程。
当然,Skill 也可以用来扩展 Agent 的工具、MCP 使用边界,通过文档与脚本,也可以教会 Agent 连接并使用特定的外部工具、MCP 服务。
举个例子,这是 PPTX Skill 的文件目录:
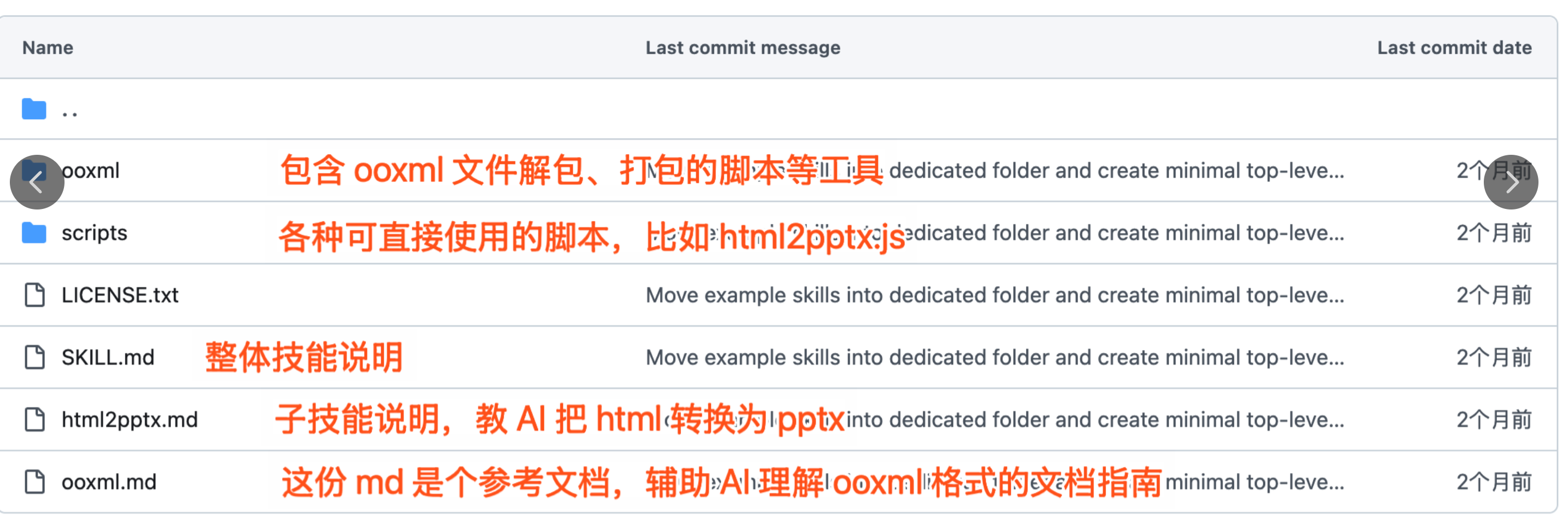
整个文件夹就是一个完整的能力包,用来支持 AI 创建、编辑和分析 PowerPoint 演示文稿。
核心文件是
SKILL.md,包含技能的元数据和任务指导,告诉 agent 什么时候使用这个技能、如何按步骤处理任务。特别的,独立子技能往往会被拆为子文档(如教 AI 把 html 导出为 pptx 流程的html2pptx.md),以避免一次性加载过长的 skill 文档,节省上下文窗口Scripts/包含 Agent 可用的各类预先写好的程序脚本,比如 html 转 pptx 的一键程序脚本。这样 Agent 运行任务时就无需临时开发工具,直接调用,节省 tokens ,避免出错,提升速度也有一些参考文档(此项目打包的不算规范,但根据 SKILL.md ,Agent 也能理解哪些文档可以参考),比如 ooxml.md,是对 ooxml 格式文件的解析指南
整个 Skill 以简明的形式,把技能指引文档、代码脚本、参考文档和可用资源组合,定向扩展了 Agent 完成 pptx 生成相关的工作能力。
☞ Skills 核心运行机制:渐进式披露
正如 《有效的 Context 工程》 文中所论证的,上下文过长容易导致模型能力下降。
由于 Skills 的本质就是 Context 工程,所以这个问题也需在 Skill Agent 中注意。
一个完整装载了 Skill 的 Agent 架构是这样的:

Skill 包放在 Agent 文件系统(右侧)中,并非默认全量加载在 Context Window 中。
根据 Context 加载顺序、优先级的不同,Skill 被划分为了 3 种层级:

Skill 内容物的 3 种渐进披露优先级

1)Level 1(元数据,始终加载):
SKILL.md 文档内的元数据,包含名称与用途描述。
长度约 100 tokens。
Agent 启动时,就在 Context Window 中加载 Skill 元数据,将其包含在系统提示中。
AI 通过理解用户消息与 Skills 元数据的匹配情况,判断是否需要自动使用技能。
---
name: pdf
description: 全面的 PDF 操作工具包,用于提取文本和表格、创建新 PDF、合并/拆分文档以及处理表单。当 Claude 需要填写 PDF 表单或大规模地程序化处理、生成或一般包含工作流程、最佳实践和指导。
建议少于 5000 tokens。
当用户发出的消息与Skill 元数据的描述匹配,需要调用 Skill 时,Agent 才会用 bash 读取文档正文 。读取时文档内容加载到 Context Window 中。

SKILL.md 的结构:分为 YAML 元数据与 MD 正文
3)Level 3(子技能指令 / 资源 / 代码,按需动态加载):
由子技能文档、代码脚本、参考文档、可用资源等文件构成。
也有 Agent Skill 规范文档将它们统称为「Resource」。相对来讲,Level 3 结构要求没那么严谨。
· Sub-SKILL.md 子技能文档:相对独立、复杂的子技能指令,单独放在 Level3 拆分加载

随着一个 Skill 的复杂度提升,可能因为技能知识的上下文过长,或者有些知识仅在特定场景使用,而不适合放入单个SKILL.md,可被分拆为独立指令文档,仅在必要时加载。
· Scripts 代码脚本:视作“Agent 的可执行资源”,而不算 tool use(tool use 是 Agent 外部调用的独立服务)
Agent 在 Agent 电脑(虚拟机)中直接调用脚本,脚本代码本身不进 Context Window,只有脚本运行完成后的输出会进 Agent 的 Context。
· Reference 参考文档、Assets 可用资源,当然都是 Level 3,仅在必需时动态读取加载。
Level 3 因为按需加载的特性,文件在被访问前不会占用 Context 长度,所以没有内容大小限制,可按业务实际说明需要添加材料。
⬇️
小结:整个 Skill 运行过程中,Agent 自动判断哪些技能与任务相关,根据 skills 的元信息,动态判断、加载完成任务所需模块:
Level 1: SKILL.md 元数据(name + description)
↓
Level 2: SKILL.md 完整内容
↓
Level 3: Resources 中的具体文件(按需读取)三、作用和特点
作用
特点和使用场景
适用于复杂的重复场景
得益于渐进式披露机制的特点可以实现按需加载,能够有效缓解上下文限制
四、如何制作一个Agent Skills
在介绍如何制作Agent Skills之前在回顾一下Skills的基本结构,构建Skills同样遵循其结构设定来搭建。
1、Skill 的最小结构
my-skill/
└── SKILL.md (唯一必需)详细结构:
my-skill/
├── SKILL.md # [必需] 核心指令文件
├── scripts/ # [可选] 可执行脚本
│ ├── processor.py
│ ├── validator.js
│ └── setup.sh
├── references/ # [可选] 参考资料
│ ├── style-guide.md
│ └── api-spec.json
└── assets/ # [可选] 静态资源
├── template.html
└── config.yamlSKILL.md 基本模板:
---
name: your-skill-name
description: What it does and when Claude should use it
---
# Skill Title
## Instructions
Clear, concrete, actionable rules.
## Examples
- Example usage 1
- Example usage 2
## Guidelines
- Guideline 1
- Guideline 2元数据字段:
SKILL.md 文件的核心构成
以 Claude 的 PDF 文档编辑技能为例,Claude 原生可解析 PDF,但无法直接操作(如填写表单),该技能补足了这一短板。
核心形态:一个包含 SKILL.md 的目录
必填元数据:SKILL.md 开头的 YAML 块,需包含 name(名称)和 description(描述),启动时预加载至系统提示词

多文件 Skill(渐进式披露)
渐进式披露机制
第一层:元数据 → 让 Claude 判断技能适用场景,不加载全部内容
第二层:SKILL.md正文 → 判定相关后,载入完整上下文
第三层 +:附属文件(如forms.md)→ 按需引用,精简核心文件体积
下图显示了当用户消息触发技能时,上下文窗口如何变化:

初始状态:上下文窗口含系统提示词、技能元数据、用户指令
调用 Bash 工具读取目标 SKILL.md,触发对应技能
按需加载附属文件(如forms.md)
加载完成后执行用户任务
推荐目录结构
为避免上下文膨胀:
核心规则 →
SKILL.md详细资料 → 单独文件
实用逻辑 → 脚本执行(不加载)
推荐结构(详细结构):
my-skill/
├── SKILL.md # [必需] 核心指令文件
├── scripts/ # [可选] 可执行脚本
│ ├── processor.py
│ ├── validator.js
│ └── setup.sh
├── references/ # [可选] 参考资料
│ ├── style-guide.md
│ └── api-spec.json
└── assets/ # [可选] 静态资源
├── template.html
└── config.yaml第一个 Skill
让我们暂时忘掉复杂的创建过程,先从 使用一个现成的 Skill 开始,感受它带来的便利。
创建 Skill 目录
Skills 存放在 ~/.claude/skills/(个人全局)或项目目录下的 .claude/skills/(项目专用)。
本章节再项目目录下测试,先创建个目录 claude-test:
mkdir claude-test进入该目录,创建 skills 的目录与文件:
mkdir -p .claude/skills/python-naming-standard编写配置文件 SKILL.md
在目录下创建 SKILL.md,这是 Skill 的大脑 ,告诉 Claude 什么时候用它。
---
name: Python 内部命名规范技能
description: 当用户要求重构、审查或编写 Python 代码时,请参考此规范。
---
## 指令
1. 所有的内部辅助函数必须以 `_internal_` 前缀命名。
2. 如果发现不符合此规则的代码,请自动提出修改建议。
3. 在执行 `claude commit` 前,必须检查此规范。
## 参考示例
- 正确:`def _internal_calculate_risk():`
- 错误:`def _calculate_risk():`字段要求:
name:必须仅使用小写字母、数字和连字符(最多 64 个字符)
description:Skill 的简要描述及其使用时机(最多 1024 个字符)
创建完后文件结构如下:
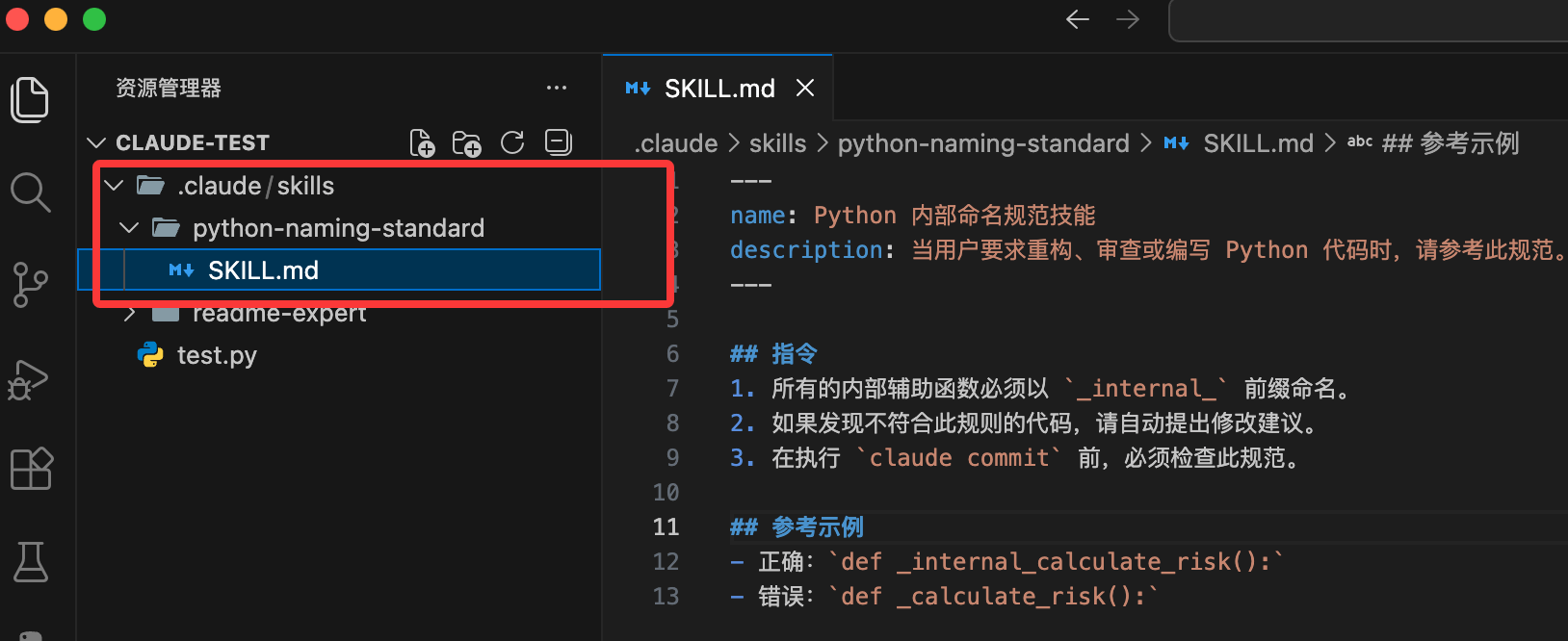
你的项目现在看起来应该是这样的:
my-project/
├─ src/
│ └─ test.py # 项目源码
├─ .claude/
│ ├─ skills/
│ │ └─ hello-world/
│ │ ├─ skill.md # Skill 定义(YAML + Instructions,机器可执行)
│ │ └─ README.md # Skill 说明(人类阅读,可选)
│ └─ config.yml # Claude 项目级配置(可选)
├─ .gitignore
└─ README.md # 项目整体说明接下来我们再终端执行以下命令启动 Claude Code:
claude输入任务:
帮我写一个计算用户折扣的函数Claude 就会会扫描已安装的 Skills,发现你的请求涉及 "Python 代码编写",匹配了 python-naming-standard。
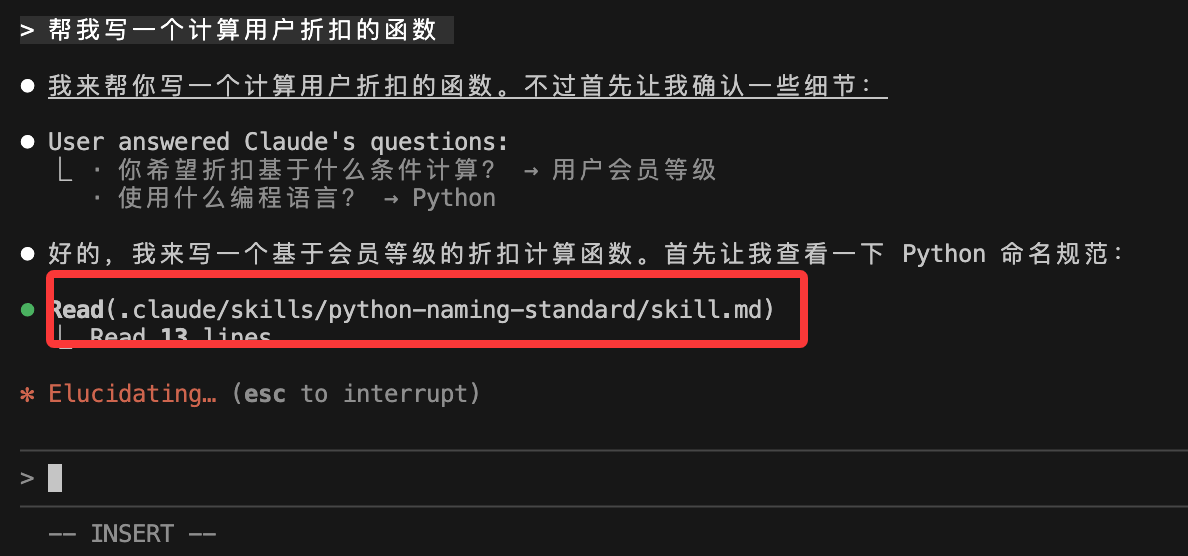
它会根据 SKILL.md 中的要求,生成如下代码:
def _internal_get_discount(user_score):
# 计算逻辑...
return discount添加资源文件(可选)
另外我们可以在 .claude/skills/ 下添加以下目录:
在同一文件夹添加:
examples/:存放示例文件。references/:存放参考文档。scripts/:存放可执行脚本(例如 Python 处理 PDF)。
然后在 SKILL.md 中引用:
查看示例 commit:./examples/good-commit.txt
运行脚本:使用工具执行 ./scripts/process.py五、如何使用Agent Skills
对于如何使用Skills这一问题,其实方法和方案有很多。主流方式还是以嵌入代码中的langchain,Function Calling,MCP以及终端类似于Claude code为主,当然还有其他方式。目前的使用方式可以参考下方表格⬇️
六、prompt、mcp、agent skills关系

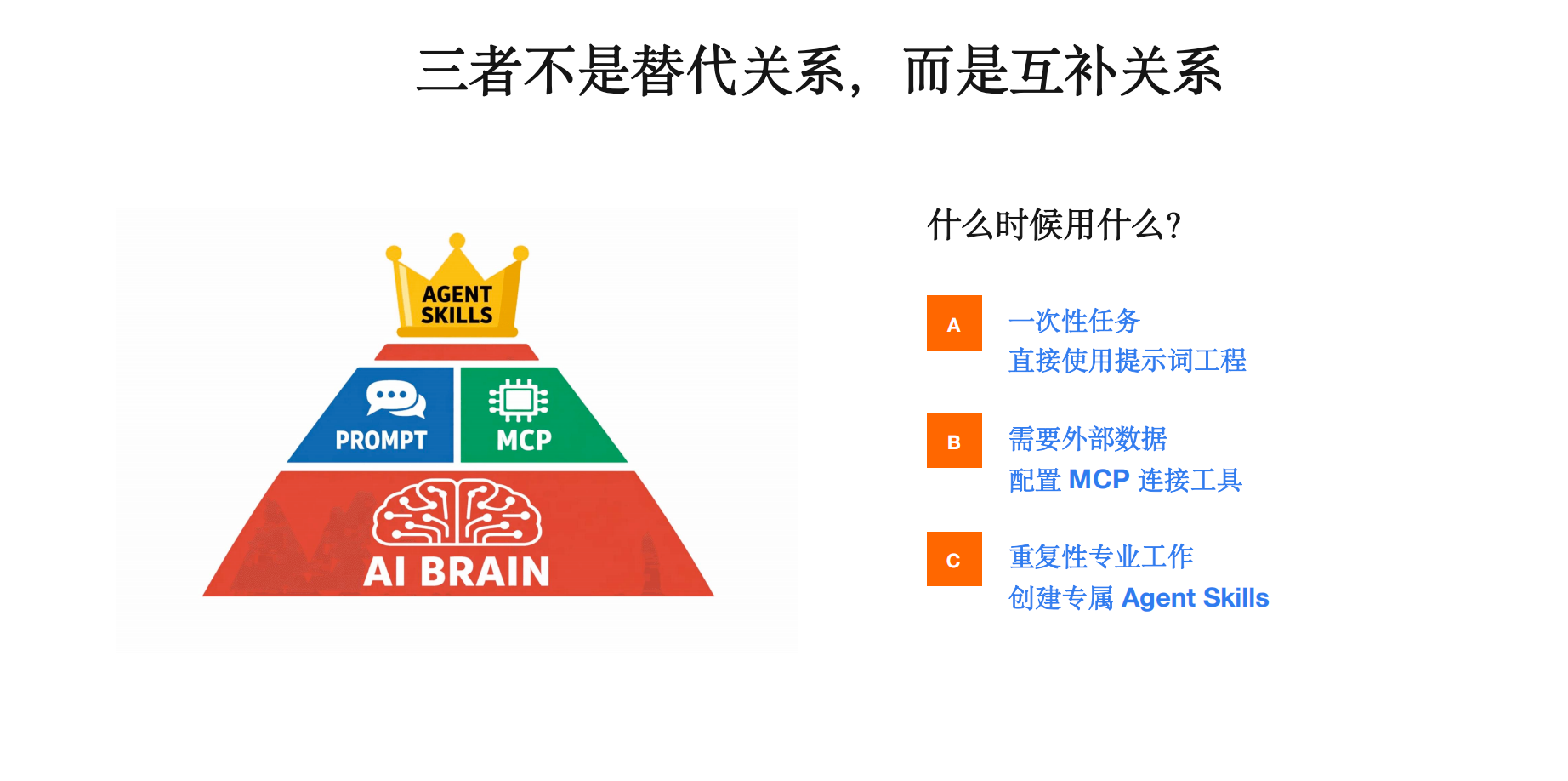
参考指南:
https://sspai.com/post/105230
https://blog.csdn.net/2401_84494441/article/details/157431905
https://zhuanlan.zhihu.com/p/2019727701573902968
