
一、基础分块与语义优化
1. Simple RAG(简单切块)
2. Semantic Chunking(语义切块)
3. Context Enriched Retrieval(上下文增强检索)
4. Contextual Chunk Headers(上下文标题)
二、检索优化与重排序
1. Document Augmentation(文档增强)
2. Query Transformation(查询转换)
3. Reranker(重排序)
4. RSE(Re-ranking with Semantic Expansion)
三、智能路由与自反思机制
1. Feedback Loop(反馈闭环)
2. Adaptive RAG(自适应检索增强生成)
3. Self RAG(自反思检索增强生成)
4.智能决策:Agentic RAG(智能体RAG)
四、结构化与多源融合
1. Knowledge Graph(知识图谱)
2. Hierarchical Indices(层次化索引)
3. HyDE(假设文档嵌入)
4. Fusion(融合检索)
五、纠错与多模态扩展
1. CRAG(纠错型 RAG)
2. Multi-Model RAG(多模态检索增强生成)
六、总结与展望
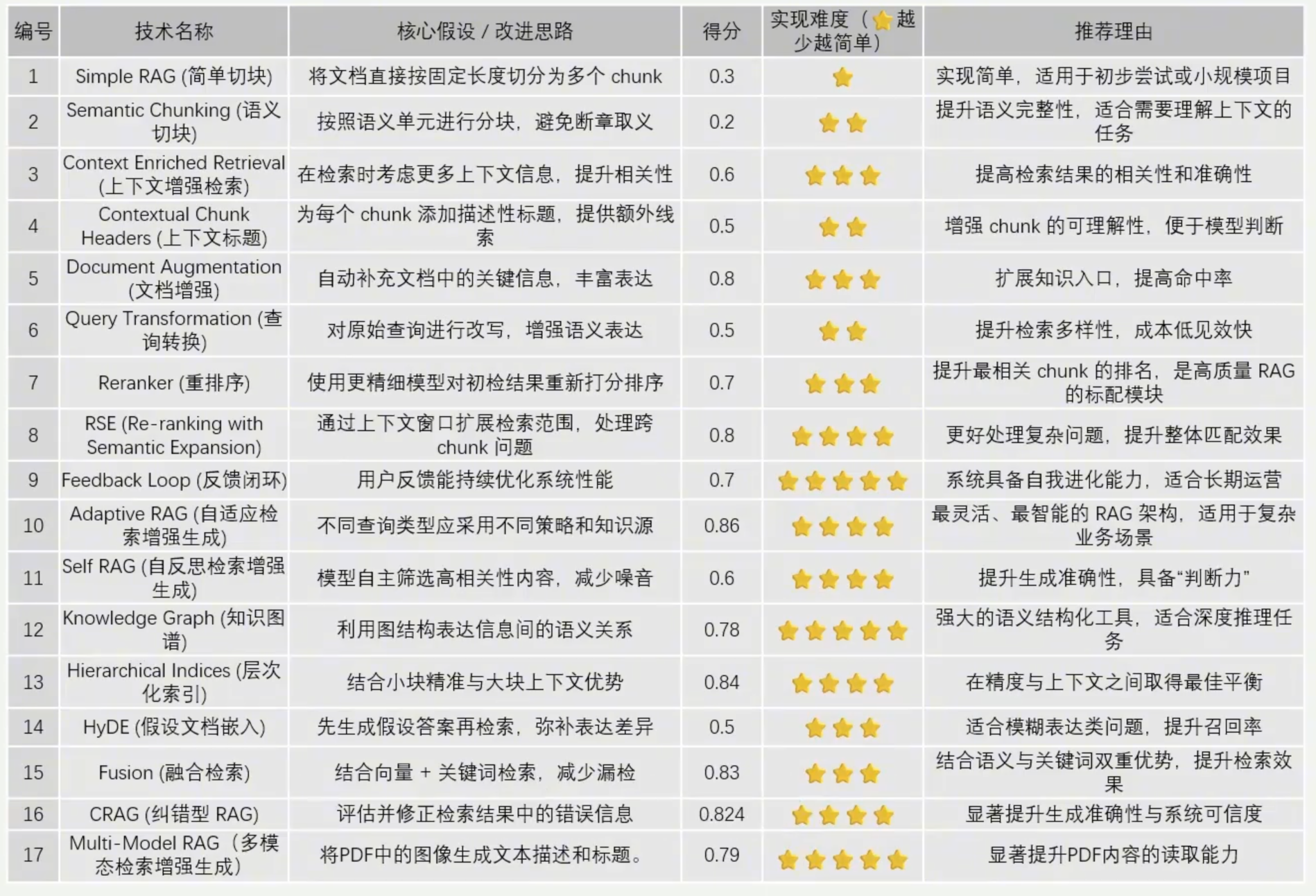
近年来,随着大语言模型(LLM)的广泛应用,检索增强生成(Retrieval-Augmented Generation,RAG)系统逐渐成为连接私有知识库与智能问答的核心架构。RAG 不仅弥补了大模型在实时性与事实性上的不足,也通过多种技术路径不断演进,形成了丰富的方法体系。
本文基于一份内部技术评估表,系统梳理了当前主流的 RAG 技术路线,并对其核心思路、实现难度与应用场景进行解读。
一、基础分块与语义优化
1. Simple RAG(简单切块)
核心思路:将文档按固定长度切分为多个 chunk,直接用于检索。 切分策略包括:按字数切块、按分句切块、按分段切块
优点:实现简单,适合小规模项目或初步验证。
局限:容易割裂语义,导致上下文丢失。
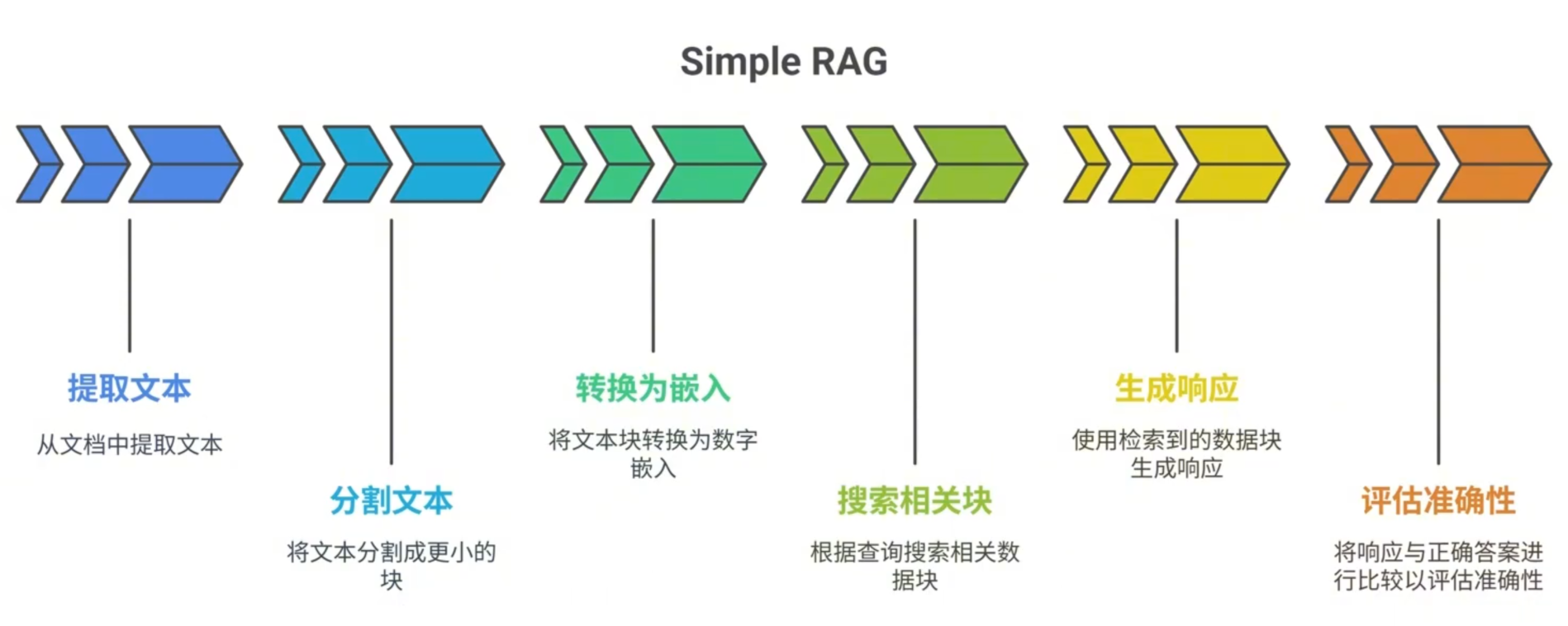
架构图:
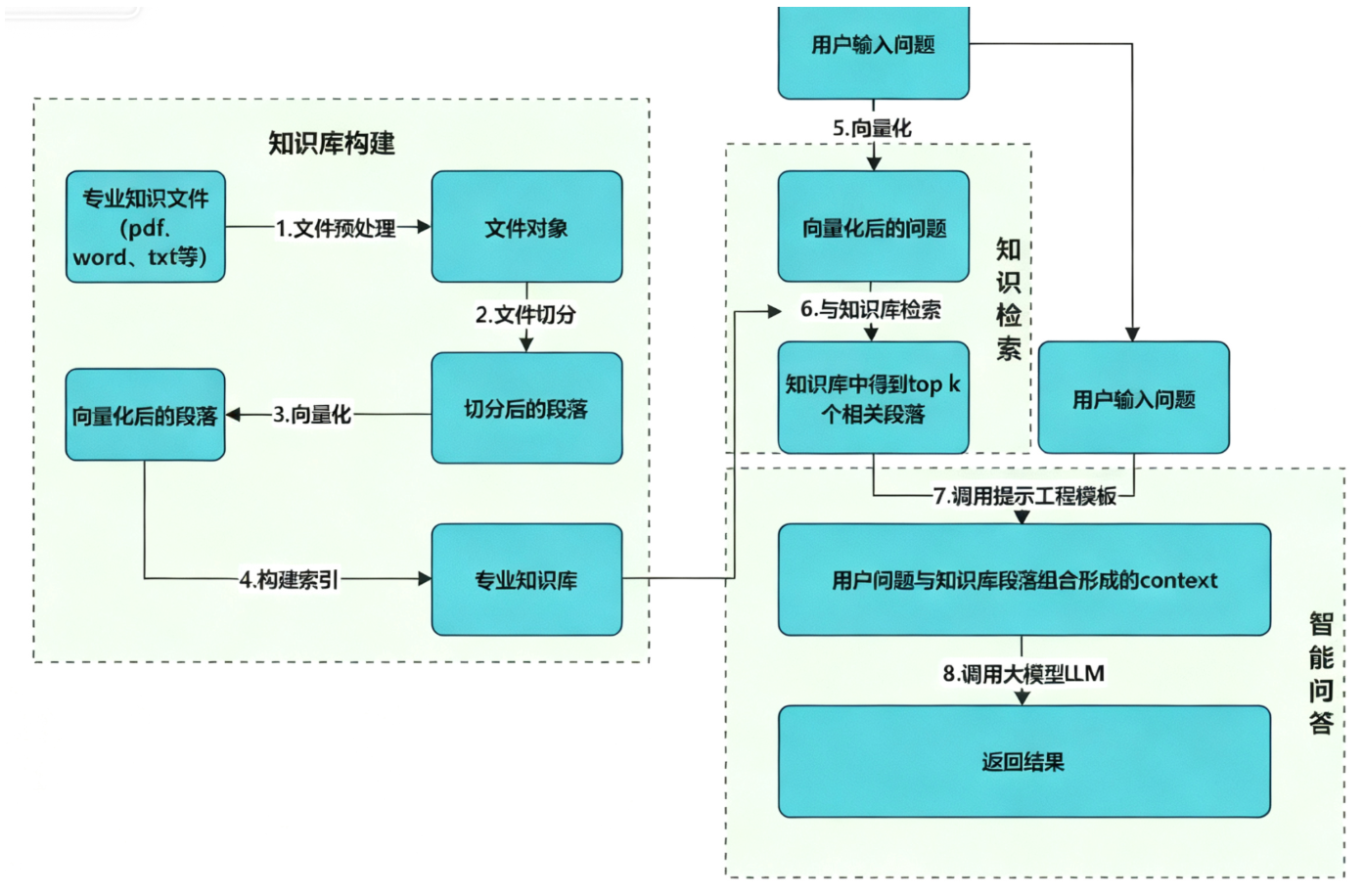
核心实现步骤
数据加载与清洗:收集目标文档数据,完成格式转换(如PDF转文本)、OCR文字提取、去噪等预处理操作,确保数据可用性。
文档分块与Embedding:将清洗后的文档拆分为更小的文本片段(Chunk),既可以让Embedding模型更精准地捕捉语义信息,也能适配大模型的上下文长度限制;随后通过Embedding模型将文本片段转换为向量。
向量存储:将生成的文本向量存入向量数据库(本文选用轻量高效的LanceDB),实现向量的快速检索。
检索与Prompt工程:接收用户查询后,先通过向量数据库检索Top-K相关文本片段;再将检索结果与查询需求整合为Prompt,传递给大模型。
答案生成:大模型基于Prompt中的上下文信息,生成准确的回答并输出。
示例:
回答用户的问题:“北京有什么著名的景点?”


评估结果: 0.3/1.0
LangChain完整实现代码
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
import lancedb
class NaiveRAG:
def __init__(self):
# 初始化大模型(选用gpt-5,温度设为0保证输出稳定)
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
# 选用轻量级Embedding模型all-MiniLM-L6-v2(仅80MB,CPU可运行)
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
# 连接LanceDB向量数据库(本地存储,无需额外部署)
self.db = lancedb.connect("/tmp/lancedb_naive_rag")
self.vectorstore = None
def build_index(self, documents: list):
"""构建向量索引:将文档转换为向量并存储"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="naive_rag_docs"
)
def query(self, question: str) -> str:
"""执行检索并生成答案"""
# 构建检索器,获取Top-3相关文档
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})
# 定义Prompt模板,明确大模型任务边界
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="""基于以下上下文回答问题,仅使用上下文信息,不要编造内容:
上下文: {context}
问题: {question}
答案:"""
)
# 构建检索-生成链
qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff", # stuff模式:将所有检索文档塞入Prompt
retriever=retriever,
chain_type_kwargs={"prompt": prompt_template}
)
return qa_chain.invoke({"query": question})["result"]
# 快速使用示例
if __name__ == "__main__":
naive_rag = NaiveRAG()
# 模拟文档数据(实际使用时替换为真实业务文档)
naive_rag.build_index(["文档1内容:租赁协议相关条款...", "文档2内容:设备维护说明...", "文档3内容:费用结算规则..."])
answer = naive_rag.query("What is issue date of lease?")
print("答案:", answer)
2. Semantic Chunking(语义切块)
核心思路:依据句子或段落语义边界进行分块,避免断章取义,可以更好地保持信息的完整性和相关性。
适用场景:需理解上下文的任务,如问答、摘要生成。
示例:

评估结果: 0.2/1.0
3. Context Enriched Retrieval(上下文增强检索)
核心思路:在检索时引入更多上下文信息,提升 chunk 的相关性。 在检索过程中,除了返回最匹配的Chunk,还同时返回其前后的相邻chunk,以提供更丰富的上下文信息。
价值:显著提高检索准确率,是高质量 RAG 的基础模块。
示例:

评估结果: 0.6/1.0
4. Contextual Chunk Headers(上下文标题)
核心思路:为每个 chunk 添加描述性标题,提供语义线索。 此标题作为额外的元信息,在检索时可作为关键词或语义线索使用。
作用:增强模型对 chunk 内容的理解能力,提升匹配质量。
目的:
增强chunk的可检索性
提供更丰富的语义提示
提高检索系统的匹配准确率
示例:


评估结果: 0.5/1.0
二、检索优化与重排序
1. Document Augmentation(文档增强)
核心思路:自动补充文档中的关键信息,扩展知识表达方式。 在原始文档的基础上,自动生成与其内容相关的问题-答案对或潜在查询语句,并将这些“虚拟查询”作为额外的检索入口加入到知识库中。
效果:增加知识入口,提高命中率。
问题背景: 如何在用户提问方式多样、关键词不一致的情况下、仍能准确地找到相关知识?
目的:
提高系统对不同表达方式的鲁棒性
扩展检索入口,提高匹配准确率
增强模型对上下文的理解能力
示例:
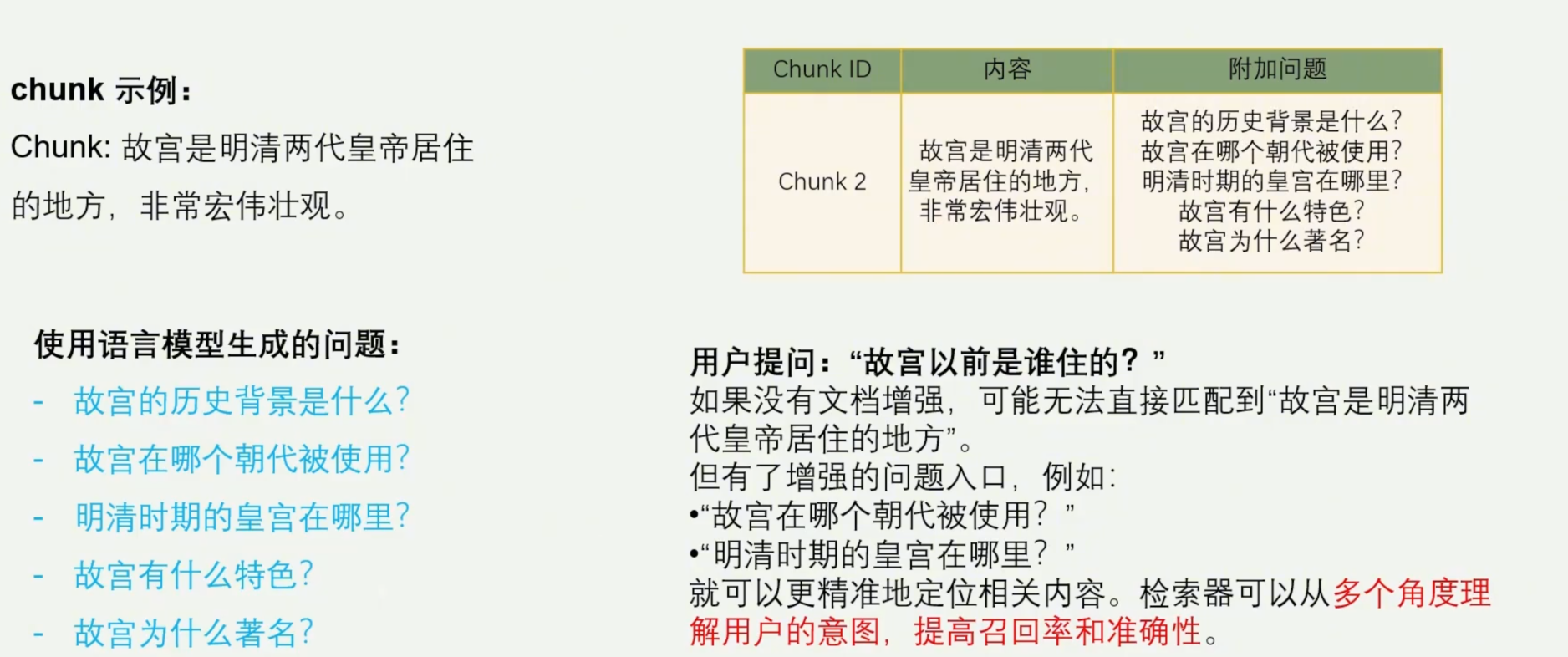
评估结果: 0.8/1.0
2. Query Transformation(查询转换)
核心思路:对用户查询进行改写或扩展,增强语义表达。
优势:低成本、见效快,适用于语义模糊的查询。
目的:
提高检索器的召回率和准确率
增强模型对模糊提问、口语化表达的理解能力
拓展多种检索路径,应对不同表达方式。

示例:

评估结果: 0.5/1.0
3. Reranker(重排序)
核心思路:使用更精细的模型**对初步检索结果重新打分排序**。 在初步检索出Top-K个候选chunk后,使用更精细的语义模型对这些候选进行重新打分和排序,以提升最相关内容的排名。
定位:高质量 RAG 系统的标配模块,显著提升 Top-K 相关性。
目的:
提高最终召回内容的相关性
弥补向量相似度排序的局限性
增强问答系统的准确率和用户体验

示例:

评估结果: 0.7/1.0
4. RSE(Re-ranking with Semantic Expansion)
核心思路:通过扩展上下文窗口,处理跨 chunk 的复杂问题。 是一种结合向量检索、语义相似度分析与上下文连贯性判断的检索增强技术,不仅关注单个Chunk的相关性,还通过“向上查找”机制,寻找与其语义连贯的相邻片段,形成更完整的上下文。
适用场景:需多段信息联合推理的任务。、
核心思想:
相关信息可能跨越多个chunk
单一chunk可能不足以表达完整语义
利用上下文窗口进行语义扩展,提升整体匹配效果。
示例:


评估结果: 0.8/1.0
三、智能路由与自反思机制
1. Feedback Loop(反馈闭环)
核心思路:收集用户反馈并持续优化检索与生成过程。
价值:系统具备自我进化能力,适合长期运营场景。
目的:
提高问答系统的准确性和相关性
实现系统的自我进化能力
持续提升用户体验与满意度
示例:



评估结果: 0.7/1.0
2. Adaptive RAG(自适应检索增强生成)
核心思路:根据查询类型动态选择检索策略与知识源。 根据用户查询类型、意图或复杂程度,动态选择不同检索策略、模型配置和知识库来源。
评分:0.86(最高),适用于复杂、多变的业务场景。
核心思想:
查询不是单一类型的
检索不应“一刀切”
应根据不同场景,使用最合适的方法
示例:


评估结果: 0.86/1.0
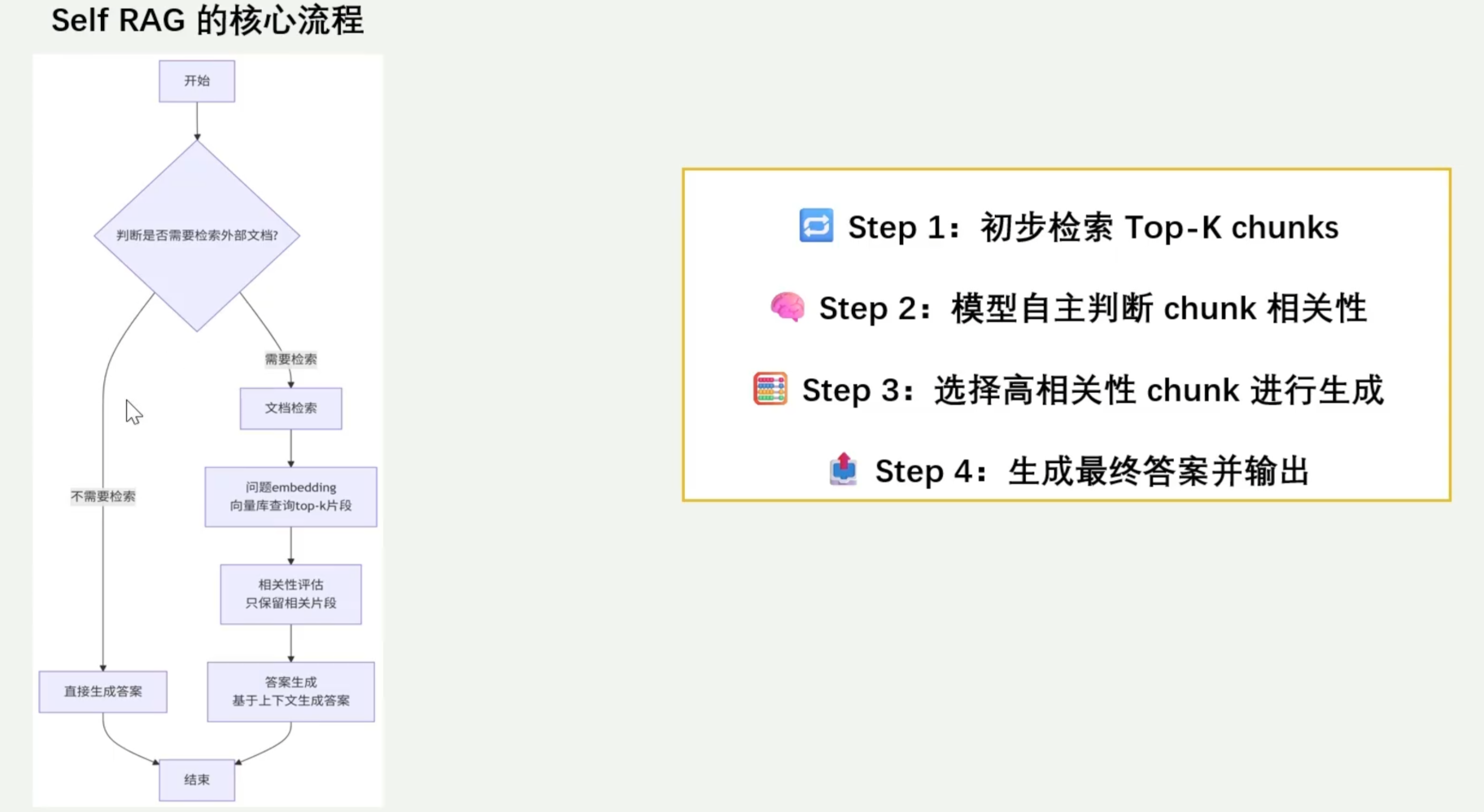
3. Self RAG(自反思检索增强生成)
核心思路:模型自主判断检索内容的相关性,筛选高价值信息。 是一种具备“自反思”机制的RAG架构,它不仅依赖外部知识库进行信息检索,还能通过语言模型自身的判断能力,对检索结果进行筛选、评估、过滤,从而只使用最相关的片段来生成答案。
特点:具备“判断力”,减少噪声,提升生成准确性。
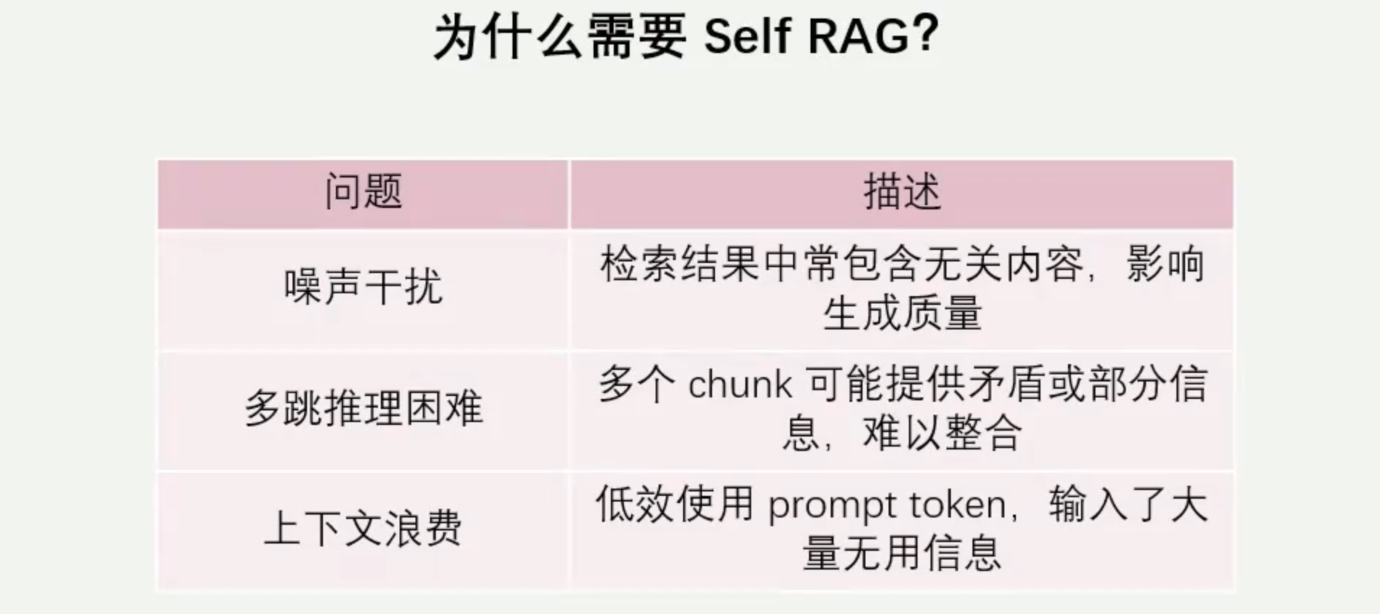
示例:
评估结果: 0.6/1.0
4.智能决策:Agentic RAG(智能体RAG)
核心简介
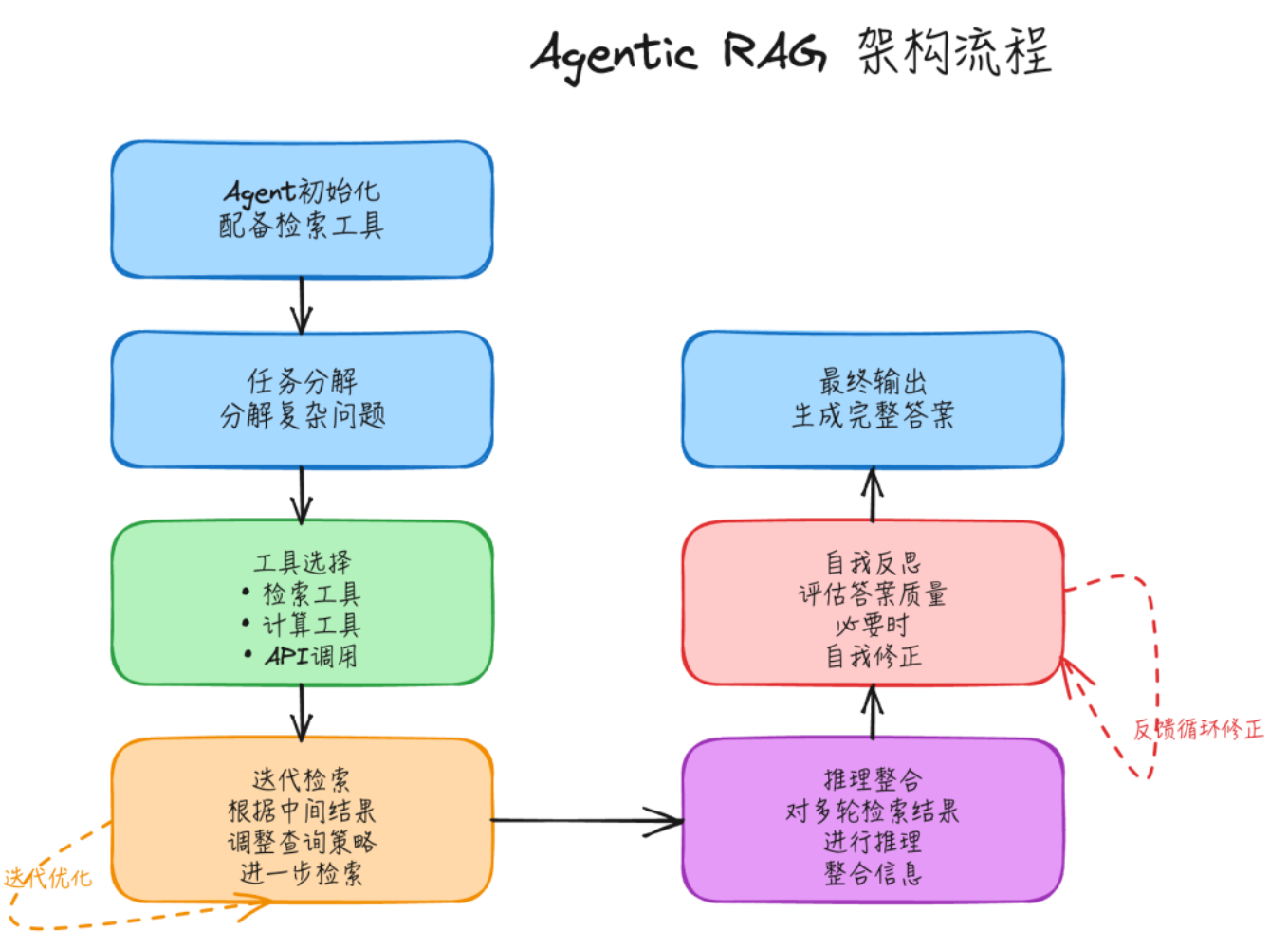
Agentic RAG将AI智能体的“规划、推理、工具调用”能力与传统RAG结合,让系统具备自主决策能力。智能体可自主分析查询意图、分解复杂任务、选择合适的工具(语义检索、关键词检索、计算器等),并根据中间结果迭代优化检索策略。适合处理复杂多步骤查询,如多条件数据分析、跨领域知识整合、流程化问答等场景。
架构示意图:
核心实现步骤
智能体初始化:创建具备推理和规划能力的AI智能体,配置多种可用工具(检索工具、计算工具、API调用工具等)。
任务分解:智能体分析用户查询,将复杂问题拆解为多个可执行的子任务(如“计算总价”“查询优惠政策”)。
工具选择:根据子任务特性,自主选择合适的工具(如数学计算选择计算器,信息查询选择语义检索)。
迭代检索与执行:智能体调用工具执行子任务,根据中间结果判断是否需要进一步检索或调整策略(如检索结果不足时重新优化查询词)。
推理整合:对多轮工具调用结果进行整合推理,形成完整的解决方案。
自我反思与修正:评估答案质量,若存在不足则重新调整步骤,最终生成准确答案。
LangChain完整实现代码
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain.tools import tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
import lancedb
from typing import List
class AgenticRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0) # GPT-4具备更强的推理能力
# 轻量级Embedding模型,适配CPU
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_agentic_rag")
self.vectorstore = None
self.agent_executor = None # 智能体执行器
def build_index(self, documents: List[str]):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="agentic_rag_docs"
)
def setup_agent(self):
"""配置智能体及可用工具"""
vectorstore = self.vectorstore # 闭包引用,让工具可访问向量库
# 工具1:语义检索(用于理解查询语义,查找相关文档)
@tool
def semantic_search(query: str) -> str:
"""语义检索工具:适用于需要理解问题含义的信息查询,返回相关文档内容"""
docs = vectorstore.similarity_search(query, k=3)
return "\n".join([f"相关文档:{d.page_content}" for d in docs])
# 工具2:关键词检索(用于精确匹配特定术语、名称的查询)
@tool
def keyword_search(query: str) -> str:
"""关键词检索工具:适用于精确匹配特定术语、名称的查询,返回精准匹配结果"""
# 简单实现:基于关键词过滤检索结果
docs = vectorstore.similarity_search(query, k=2)
filtered_docs = [d.page_content for d in docs if query in d.page_content]
return "\n".join([f"精准匹配文档:{doc}" for doc in filtered_docs]) if filtered_docs else "无精准匹配结果"
# 工具3:计算器(用于处理数学计算类子任务)
@tool
def calculator(expression: str) -> str:
"""计算器工具:用于执行数学计算,输入合法的数学表达式(如100+200)"""
try:
# 限制计算范围,避免安全风险
allowed_ops = {"+", "-", "*", "/", "(", ")"}
if all(c in allowed_ops or c.isdigit() or c == "." for c in expression):
return f"计算结果:{str(eval(expression))}"
else:
return "不支持的计算符号,仅允许+、-、*、/"
except Exception as e:
return f"计算错误:{str(e)}"
# 配置工具列表
tools = [semantic_search, keyword_search, calculator]
# 定义智能体提示模板,明确其角色和工具使用规则
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个具备规划和工具调用能力的智能助手,负责解决用户的复杂问题。
可用工具说明:
1. semantic_search:语义检索,用于理解问题含义并查找相关文档(如“产品A和B的优惠政策”);
2. keyword_search:关键词检索,用于精确匹配特定术语(如“产品A价格”);
3. calculator:计算器,用于数学计算(如“100+200”)。
工作流程:
1. 分析用户问题,拆解为子任务;
2. 为每个子任务选择合适的工具;
3. 调用工具获取结果,若结果不足则调整策略重新调用;
4. 整合所有结果,生成完整答案。
注意:仅在需要时调用工具,无需调用工具即可回答的问题直接回答。"""),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad") # 智能体思考过程记录
])
# 创建工具调用型智能体
agent = create_tool_calling_agent(self.llm, tools, prompt)
# 配置智能体执行器,设置最大迭代次数避免死循环
self.agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 开启 verbose 查看智能体思考和工具调用过程
max_iterations=5,
handle_parsing_errors="返回'无法解析请求,请重新表述问题'"
)
def query(self, question: str) -> str:
"""执行查询,智能体自主完成任务"""
if not self.agent_executor:
self.setup_agent() # 初始化智能体
result = self.agent_executor.invoke({"input": question})
return result["output"]
# 使用示例
if __name__ == "__main__":
arag = AgenticRAG()
# 导入业务文档(产品价格、优惠政策等)
arag.build_index(["产品A价格100元,购买2件以上9折优惠...", "产品B价格200元,新用户立减30元...", "企业客户额外享受8折优惠..."])
# 复杂查询:包含计算和信息检索
answer = arag.query("新用户购买1件产品A和1件产品B的总价是多少?有哪些优惠可以享受?")
print("答案:", answer)
四、结构化与多源融合
1. Knowledge Graph(知识图谱)/GraphRAG
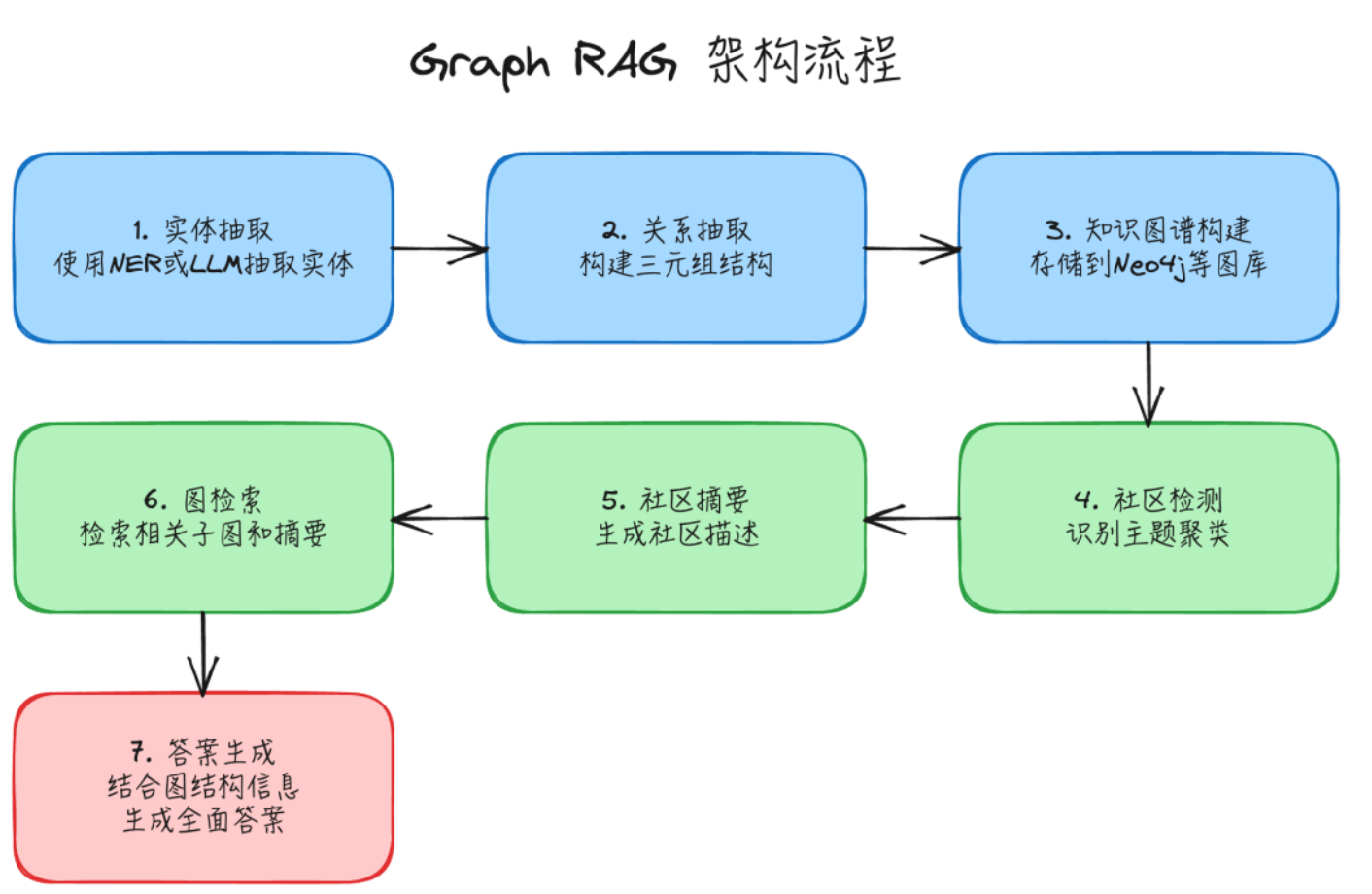
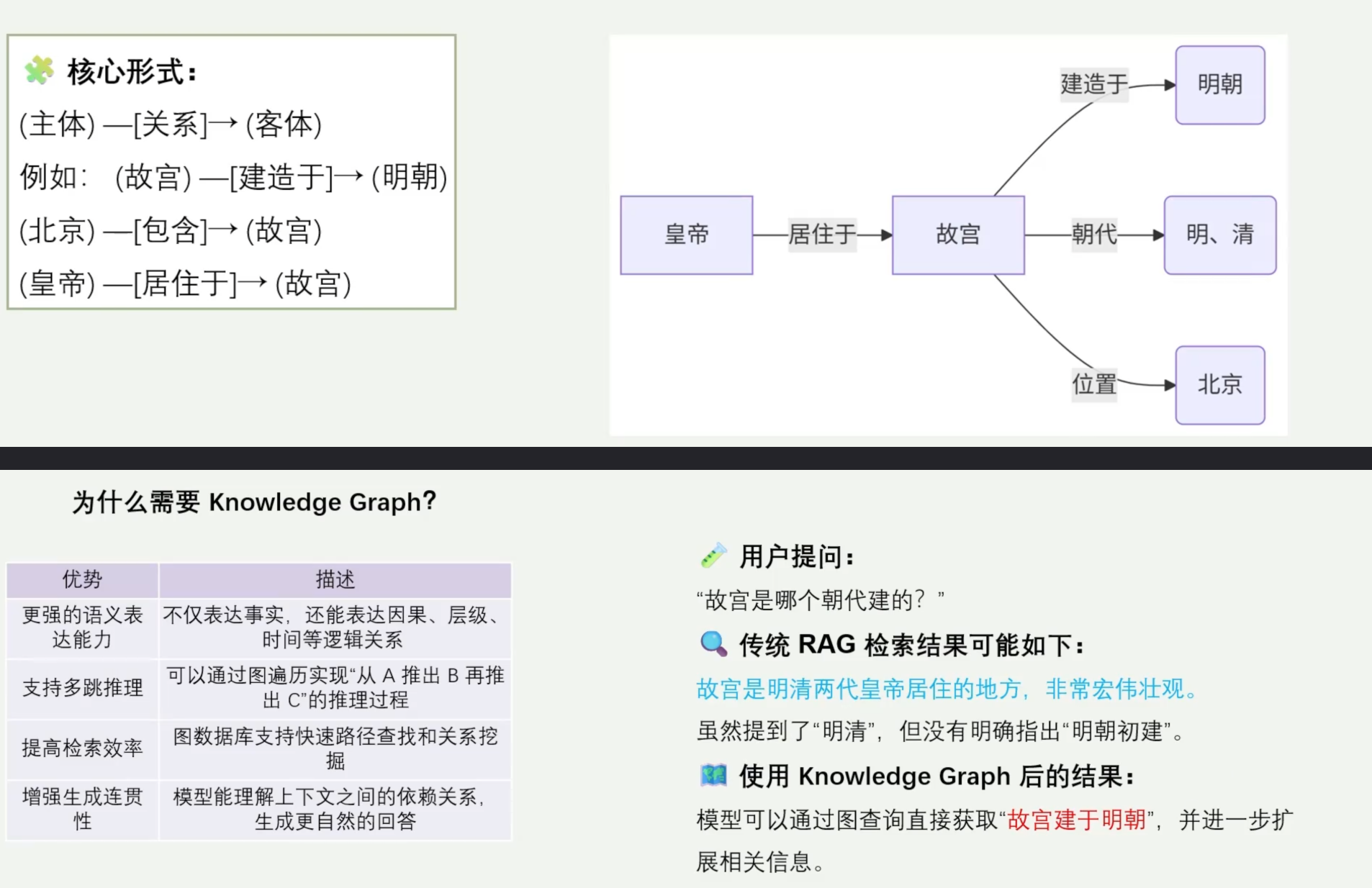
核心思路:利用图结构建模实体与关系,支持深度推理。 通过实体(Entity)、关系(Relation)、属性(Attribute)三元组来表达现实世界中事物之间的语义联系。/或者说Graph RAG将知识图谱技术与传统RAG结合,通过从文档中抽取实体(如人物、企业、概念)和实体关系(如“任职于”“位于”),构建结构化的知识图谱,再结合社区检测、子图检索等技术提升检索的精准性。相比传统RAG的文本片段检索,Graph RAG能更好地捕捉实体间的关联关系,适合处理需要结构化知识的场景,如企业关系分析、学术概念关联查询、历史事件梳理等。
适用任务:复杂问答、因果推断、关系查询。
架构示意图:
核心实现步骤
实体与关系抽取:利用命名实体识别(NER)工具或大模型,从文档中提取实体(如“张三”“ABC公司”)和实体间的关系(如“是…CEO”“位于”),形成三元组(实体-关系-实体)。
知识图谱构建:将抽取的实体和关系存储到图数据库(如Neo4j)中,构建结构化的知识图谱;同时可使用NetworkX构建本地图,用于快速社区检测。
社区检测:对知识图谱进行社区划分,识别主题相近的实体聚类(如“ABC公司相关人员”“产品X相关技术”)。
社区摘要:为每个实体社区生成摘要,概括社区核心内容,便于快速理解主题。
图检索:根据用户查询提取关键实体,在知识图谱中检索相关子图和对应社区摘要。
答案生成:结合子图的结构化关系信息和社区摘要,生成逻辑清晰、关联明确的答案。
示例:
评估结果: 0.78/1.0
LangChain完整实现代码
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import networkx as nx
from typing import List, Dict
import json
class GraphRAG:
def __init__(self, neo4j_uri="bolt://localhost:7687",
neo4j_user="neo4j", neo4j_password="password"):
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
# 连接Neo4j图数据库(需提前安装并启动Neo4j)
self.graph_db = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password
)
self.nx_graph = nx.Graph() # 本地NetworkX图,用于社区检测
def extract_entities_and_relations(self, text: str) -> Dict:
"""使用大模型从文本中抽取实体和关系,返回JSON格式结果"""
prompt = ChatPromptTemplate.from_template(
"""从以下文本中精准提取实体和实体关系,严格按照指定JSON格式返回,不添加任何额外内容:
文本: {text}
返回格式(仅JSON):
{{
"entities": ["实体1", "实体2", ...],
"relations": [["实体1", "关系类型", "实体2"], ...]
}}"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"text": text})
try:
return json.loads(response)
except json.JSONDecodeError as e:
print(f"实体关系提取失败:{e}")
return {"entities": [], "relations": []}
def build_knowledge_graph(self, documents: List[str]):
"""构建知识图谱,同时存储到Neo4j和本地NetworkX"""
for doc in documents:
extracted = self.extract_entities_and_relations(doc)
# 1. 添加到本地NetworkX图(用于快速社区检测)
for entity in extracted["entities"]:
self.nx_graph.add_node(entity)
for rel in extracted["relations"]:
if len(rel) == 3: # 确保是合法三元组
self.nx_graph.add_edge(rel[0], rel[2], relation=rel[1])
# 2. 存储到Neo4j图数据库(用于结构化检索)
# 插入实体
for entity in extracted["entities"]:
self.graph_db.query(
"MERGE (e:Entity {name: $name})", # MERGE避免重复插入
{"name": entity}
)
# 插入关系
for rel in extracted["relations"]:
if len(rel) == 3:
self.graph_db.query(
"""MATCH (a:Entity {name: $from})
MATCH (b:Entity {name: $to})
MERGE (a)-[r:RELATED {type: $rel_type}]->(b)""",
{"from": rel[0], "to": rel[2], "rel_type": rel[1]}
)
def detect_communities(self) -> List[List[str]]:
"""社区检测:使用Louvain算法划分实体社区"""
from networkx.algorithms import community
if len(self.nx_graph.nodes()) == 0:
print("知识图谱为空,无法进行社区检测")
return []
# Louvain算法:最大化模块度,实现社区划分
communities = community.louvain_communities(self.nx_graph)
return [list(c) for c in communities] # 转换为列表格式返回
def generate_community_summaries(self, communities: List[List[str]]) -> List[Dict]:
"""为每个实体社区生成摘要,概括社区核心内容"""
summaries = []
for i, comm in enumerate(communities):
# 提取当前社区的实体和关系信息
subgraph = self.nx_graph.subgraph(comm)
edges_info = [(u, v, d.get('relation', '相关'))
for u, v, d in subgraph.edges(data=True)]
# 生成社区摘要
prompt = ChatPromptTemplate.from_template(
"""请为以下实体社区生成简洁的摘要(不超过100字),说明社区内实体的核心关联:
实体列表: {entities}
实体关系: {relations}
摘要要求:简洁明了,突出核心关联,不添加无关内容"""
)
chain = prompt | self.llm | StrOutputParser()
summary = chain.invoke({"entities": comm, "relations": edges_info})
summaries.append({
"community_id": i + 1,
"entities": comm,
"summary": summary
})
return summaries
def query(self, question: str) -> str:
"""基于知识图谱的检索与回答"""
# 1. 从问题中提取关键实体
question_entities = self.extract_entities_and_relations(question)["entities"]
if not question_entities:
return "未从问题中识别到关键实体,无法检索"
# 2. 在Neo4j中检索相关子图(实体及关联关系)
graph_context = self.graph_db.query(
"""MATCH (e:Entity)-[r]-(related:Entity)
WHERE e.name IN $entities
RETURN e.name AS entity, type(r) AS relation_type, related.name AS related_entity
LIMIT 20""",
{"entities": question_entities}
)
# 3. 获取社区摘要(取前3个相关社区)
communities = self.detect_communities()
community_summaries = self.generate_community_summaries(communities[:3])
# 4. 整合图谱信息和社区摘要,生成最终答案
context = f"实体关联信息:{graph_context}\n社区摘要:{community_summaries}"
prompt = ChatPromptTemplate.from_template(
"""基于以下知识图谱信息回答问题,重点突出实体间的关联关系:
{context}
问题: {question}
答案要求:逻辑清晰,明确说明实体关联,简洁准确"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"context": context, "question": question})
# 使用示例
if __name__ == "__main__":
# 初始化GraphRAG(需提前启动Neo4j,修改为自己的Neo4j配置)
grag = GraphRAG(neo4j_uri="bolt://localhost:7687", neo4j_user="neo4j", neo4j_password="123456")
# 导入文档数据,构建知识图谱
grag.build_knowledge_graph([
"张三是ABC公司的CEO,该公司位于北京海淀区",
"李四是ABC公司的CTO,他与张三是清华大学大学同学",
"ABC公司开发了产品X,该产品采用深度学习技术,市场份额领先行业30%",
"产品X的核心研发人员包括王五,王五曾任职于谷歌研究院"
])
# 查询实体关联类问题
answer = grag.query("ABC公司的领导层有哪些人?他们之间有什么关联?")
print("答案:", answer)
2. Hierarchical Indices(层次化索引)
核心思路:结合小块的精准匹配与大块的上下文完整性。 将文本数据按不同粒度组织成“多级索引”的方式,先用大块进行初步检索,再用匹配的大块中进一步细化检索,从而实现精度与上下文之间的平衡。
核心思路:
小块用于精确匹配关键词
大块用于提供完整语境和扩展信息
通过“粗筛+细搜”两步法提升整体检索质量
优势:在精度与上下文之间取得平衡。

示例:
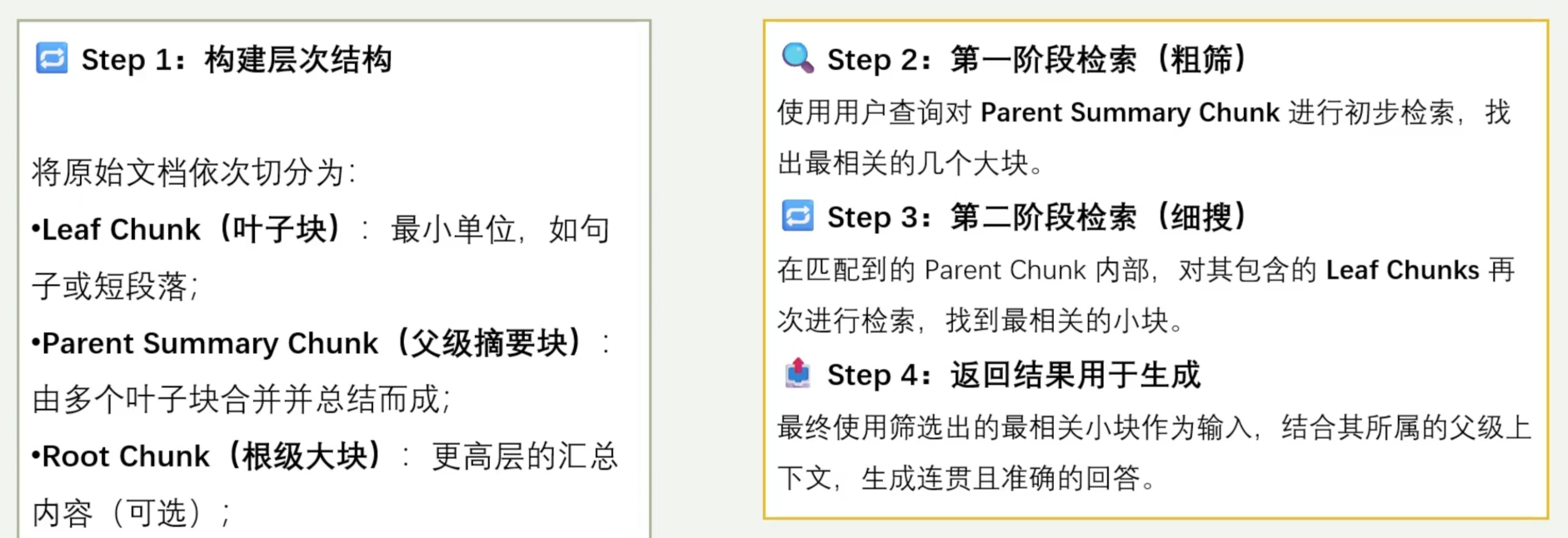
评估结果: 0.84/1.0
3. HyDE(假设文档嵌入)
核心思路:先由模型生成假设答案,再以其为查询进行检索。
核心思想:
原始查询可能模糊或表达不清
模型生成的答案更接近知识库中的表达形式
使用“假想答案”的向量去匹配知识库中真正的相关内容
适用场景:用户表达模糊、语义差距大的场景。

评估结果: 0.5/1.0
4. Fusion(融合检索)
核心思路:将多种检索方法(如向量检索、关键词检索、布尔检索等)的结果进行加权融合,利用不同方法的互补优势,减少漏检,提高整体的召回率和相关性。
核心思想:
没有一种检索方式是“万能”的
多种方法联合使用可以显著减少“漏检”
融合打分机制可更精确地排序结果
效果:兼顾语义与字面匹配,提升召回率。
示例:


评估结果: 0.83/1.0
五、纠错与多模态扩展
1. CRAG(纠错型 RAG)
核心思路:对检索结果进行可信度评估、动态筛选与主动修正,它不依赖于原始检索内容生成答案,还能:识别不可靠信息(如错误事实、过时数据)、主动触发纠错机制(如二次检索或知识修正)、基于修正后的上下文生成高准确性答案。
核心思想:
并非所有检索结果值得信任
模型需要具备“评估-纠错-生成”闭环能力(而非过滤)
生成前必须消除错误,而非事后补救。
价值:显著提升生成内容的准确性与系统可信度。
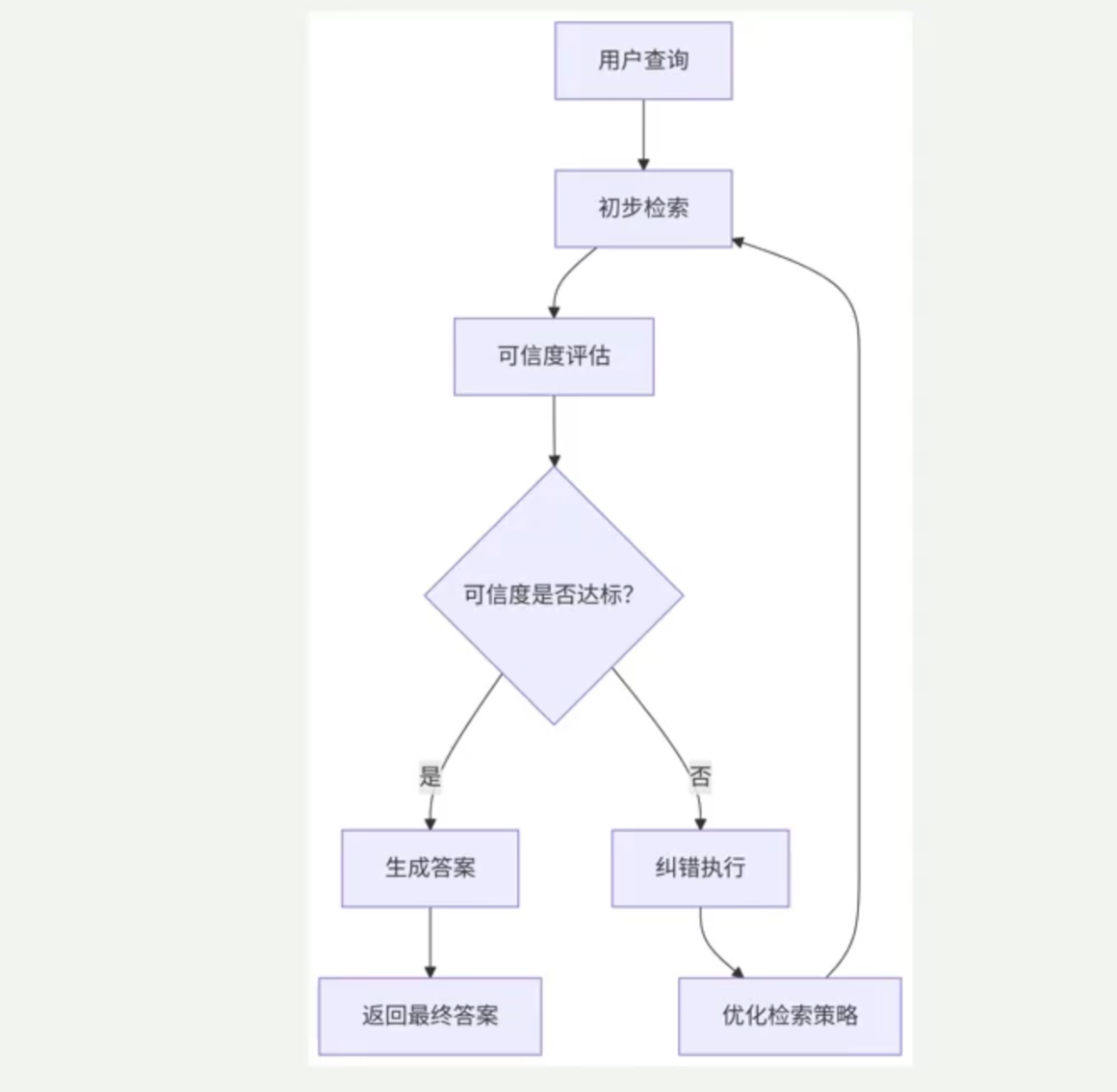
评估结果: 0.824/1.0
2. Multi-Model RAG(多模态检索增强生成)
核心思路:将图像、表格等非文本内容转化为文本描述,统一检索。 通过提取、理解并关联文档中的多模态元素(文字+图片),实现更加完整、更直观的知识服务。
核心思想:
“图文一体”:PDF中的图像不是装饰,而是关键知识载体。
“跨模态理解”:建立文本描述与图像内容的语义关联
“视觉增强生成”:在答案中智能融合文字说明与图像引用
应用场景:PDF、报告等多模态文档的理解与问答。


评估结果: 0.79/1.0
六、总结与展望
从简单的固定分块到自适应的多模态检索,RAG 技术正在向更智能、更鲁棒、更可信的方向发展。未来,我们有望看到更多融合推理、交互学习与跨模态理解的 RAG 系统,成为企业知识管理与人机协作的核心基础设施。
参考链接:https://leezhao415.blog.csdn.net/article/details/154085398
