
目录
什么是上下文窗口
上下文窗口为何会爆掉
主流解决方案全景图
方案一:重排序 + 动态截断
方案二:多级索引(父子文档)
方案三:对话记忆分层(滑动窗口+摘要)
方案四:Map-Reduce 模式
方案五:上下文压缩(LLMLingua)
方案选型指南
一、什么是上下文窗口
1.1 基本概念
上下文窗口(Context Window) 是大语言模型(LLM)在一次推理中可以处理的 最大 Token 数量。
# 简单理解
上下文窗口 = 输入Token数(你的问题 + 检索内容) + 输出Token数(模型回答)1.2 Token 是什么
Token 是模型处理文本的最小单位:
示例:
# "RAG技术很好" 的 Token 化
中文: ["RAG", "技术", "很好"] # 约 3-4 Tokens
英文: "RAG technology is good" # 约 5-6 Tokens1.3 常见模型的上下文窗口
二、上下文窗口为何会爆掉
2.1 问题示意
# 一个典型 RAG 流程的 Token 消耗
system_prompt = "你是一个AI助手..." # 500 tokens
user_query = "请总结这份财报..." # 50 tokens
retrieved_docs = """
文档块1: 财报第1-5页... # 2000 tokens
文档块2: 财报第6-10页.. # 2000 tokens
...
文档块20: 财报第95-100页 # 2000 tokens
""" # 总计 40000 tokens
total = 500 + 50 + 40000 = 40550 tokens
# 如果模型窗口是 8K,直接爆掉!2.2 爆掉的主要原因
原因 1:召回数量过多
# 常见错误:为了提高召回率,取太多文档块
retrieved_chunks = vector_store.similarity_search(query, k=50) # 50个块
# 每个块 500 tokens,总输入 = 25000 tokens原因 2:文档切块过细
# 过度切分导致大量重复上下文
chunk_size = 200 # 太小
# 100页文档 → 1500个块 → 检索50个块 → 信息碎片化严重原因 3:对话历史累积
# 多轮对话,历史消息不断累积
messages = [
{"role": "user", "content": "第一轮问题..."}, # 500 tokens
{"role": "assistant", "content": "第一轮回答..."}, # 800 tokens
{"role": "user", "content": "第二轮问题..."}, # 300 tokens
{"role": "assistant", "content": "第二轮回答..."}, # 600 tokens
# ... 50轮后,总 token 可能超过 10万
]原因 4:文档冗余
# 多个检索块包含重复内容
chunk_1 = "公司的营收为100亿,利润20亿..." # 500 tokens
chunk_2 = "本季度公司营收100亿,同比增长..." # 500 tokens
# 两块都包含"营收100亿",浪费窗口空间2.3 爆掉的后果
三、主流解决方案全景图
3.1 解决方案分类
上下文窗口管理
├── 检索前优化(预防)
│ ├── 多级索引
│ └── 查询路由
├── 检索中优化(控制)
│ └── 动态检索策略
├── 检索后压缩(处理)
│ ├── 重排序+截断 ⭐ 最主流
│ ├── 上下文压缩
│ └── 文档重组
└── 架构级方案
├── Map-Reduce
└── 对话记忆分层3.2 各方案对比速览
四、方案一:重排序 + 动态截断
4.1 方案概述
核心思想:先用高召回算法(向量检索)取足够多的候选,再用精确模型(交叉编码器)重排序,只取最相关的 Top-K 进入上下文。
为什么是主流:简单、高效、成本可控,在 80% 的 RAG 场景中够用。
4.2 技术原理
传统做法:
用户问题 → 向量检索 → 取 Top-20 → 全部塞入 LLM
↓
问题:20个块中可能只有5个有用,浪费窗口
重排序做法:
用户问题 → 向量检索 → 取 Top-50 → 重排序 → 取 Top-5 → 塞入 LLM
↓ ↓
高召回率 精排序,去冗余关键技术:
1. 向量检索(Embedding)
# 快速但粗糙
query_embedding = embed_model.encode(query)
candidates = vector_db.search(query_embedding, k=50) # 高召回2. 交叉编码器(Cross-Encoder)
# 慢速但精确,联合编码 query 和 document
def rerank(query, documents):
scores = []
for doc in documents:
# 将 query 和 document 一起编码
input = f"[CLS] {query} [SEP] {doc} [SEP]"
score = cross_encoder(input) # 输出相关性分数
scores.append(score)
return sorted(documents, key=scores, reverse=True)4.3 实现流程

4.4 代码实现
import tiktoken
from sentence_transformers import CrossEncoder
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
class RAGWithReranking:
def __init__(self, llm, vector_store, max_tokens=8000):
self.llm = llm
self.vector_store = vector_store
self.max_tokens = max_tokens
self.tokenizer = tiktoken.get_encoding("cl100k_base")
# 加载重排序模型(开源)
self.reranker = CrossEncoder('BAAI/bge-reranker-base')
def count_tokens(self, text):
return len(self.tokenizer.encode(text))
def rerank_documents(self, query, documents, top_k=5):
"""重排序"""
pairs = [[query, doc.page_content] for doc in documents]
scores = self.reranker.predict(pairs)
# 按分数排序
sorted_docs = sorted(
zip(documents, scores),
key=lambda x: x[1],
reverse=True
)
return [doc for doc, score in sorted_docs[:top_k]]
def truncate_by_token(self, documents, max_tokens):
"""Token 截断"""
truncated_docs = []
current_tokens = 0
for doc in documents:
doc_tokens = self.count_tokens(doc.page_content)
if current_tokens + doc_tokens <= max_tokens:
truncated_docs.append(doc)
current_tokens += doc_tokens
else:
# 截断最后一个文档
remaining = max_tokens - current_tokens
if remaining > 100: # 至少保留100 tokens
truncated_content = doc.page_content[:remaining * 4]
doc.page_content = truncated_content
truncated_docs.append(doc)
break
return truncated_docs
def query(self, question):
# 1. 高召回检索
candidates = self.vector_store.similarity_search(question, k=50)
# 2. 重排序,取 Top-5
reranked_docs = self.rerank_documents(question, candidates, top_k=5)
# 3. 计算剩余窗口(预留1000 tokens给 system prompt 和回答)
available_tokens = self.max_tokens - 1000
# 4. Token 截断
final_docs = self.truncate_by_token(reranked_docs, available_tokens)
# 5. 构建 Prompt
context = "\n\n".join([doc.page_content for doc in final_docs])
prompt = f"""基于以下参考资料回答问题:
参考资料:
{context}
问题:{question}
请给出准确、简洁的回答。"""
# 6. 调用 LLM
response = self.llm.invoke(prompt)
return response
# 使用示例
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", max_tokens=1000)
vector_store = Chroma(...) # 你的向量数据库
rag = RAGWithReranking(llm, vector_store, max_tokens=4000)
answer = rag.query("2023年公司营收是多少?")
print(answer)4.5 效果评估
五、方案二:多级索引(父子文档)
5.1 方案概述
核心思想:构建层次化的文档结构,小粒度检索、大粒度提供上下文,避免信息碎片化。
适用场景:长文档问答、技术文档、法律合同等需要完整上下文的场景。
5.2 技术原理
# 传统切块:信息可能被切断
文档原文:
"公司营收达到100亿。主要来源于...(中间内容)...利润20亿。"
切块1: "公司营收达到100亿。" # 只有营收,没有利润
切块2: "利润20亿。" # 只有利润,没有营收
# 父子文档:保留结构关系
父文档(段落级):
"公司营收达到100亿。主要来源于...利润20亿。" # 完整段落
子文档(句子级):
"公司营收达到100亿。" # 指向父文档1
"利润20亿。" # 指向父文档15.3 索引结构设计
python
{
"chunk_id": "chunk_001",
"content": "公司的营收达到100亿...", # 子文档内容
"type": "child",
"parent_id": "parent_001", # 指向父文档
"metadata": {...}
}
{
"chunk_id": "parent_001",
"content": "完整的段落内容...", # 父文档内容
"type": "parent",
"child_ids": ["chunk_001", "chunk_002"],
"metadata": {...}
}5.4 实现流程
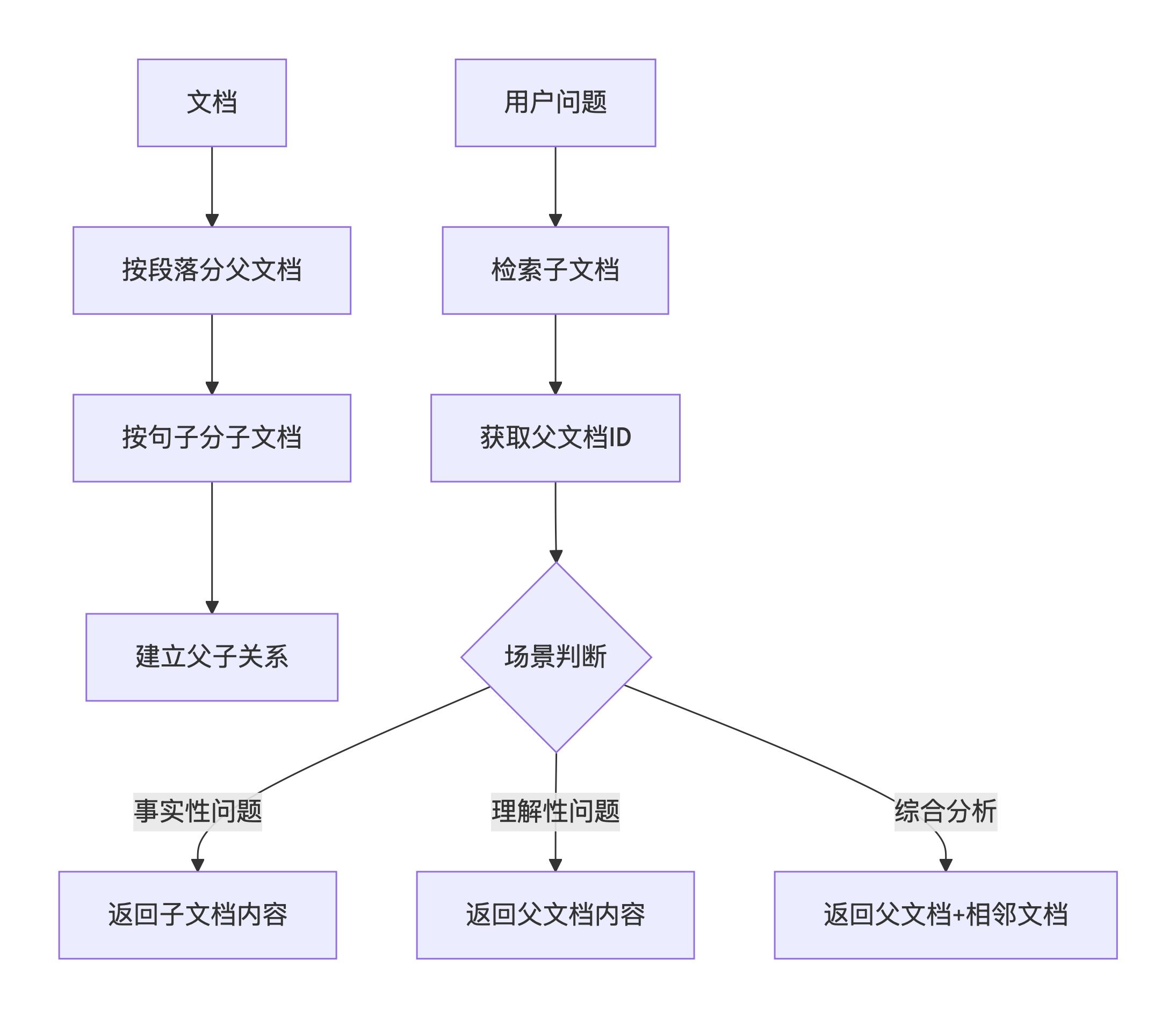
5.5 代码实现
from typing import List, Dict
import hashlib
class HierarchicalIndex:
def __init__(self, vector_store, doc_store):
self.vector_store = vector_store
self.doc_store = doc_store # 存储完整文档
def create_hierarchy(self, document: str, chunk_size: int = 1000):
"""创建父子文档索引"""
# 1. 按段落分父文档
paragraphs = document.split('\n\n')
parent_chunks = []
for para in paragraphs:
if len(para) < 100:
continue
# 父文档ID
parent_id = hashlib.md5(para.encode()).hexdigest()
# 存储父文档
parent_chunk = {
"id": parent_id,
"content": para,
"type": "parent"
}
self.doc_store[parent_id] = parent_chunk
# 2. 将父文档切分成子文档
sentences = self.split_sentences(para)
child_chunks = []
for sent in sentences:
child_id = hashlib.md5(sent.encode()).hexdigest()
child_chunk = {
"id": child_id,
"content": sent,
"type": "child",
"parent_id": parent_id
}
# 子文档存入向量库
self.vector_store.add_texts(
[sent],
metadatas=[{"parent_id": parent_id, "chunk_id": child_id}]
)
child_chunks.append(child_chunk)
parent_chunk["child_ids"] = [c["id"] for c in child_chunks]
return parent_chunks
def split_sentences(self, text: str) -> List[str]:
"""简单分句(生产环境建议用 spacy/nltk)"""
import re
sentences = re.split(r'[。!?.!?]', text)
return [s.strip() for s in sentences if s.strip()]
def retrieve_with_context(self, query: str, strategy: str = "parent"):
"""根据策略检索"""
# 1. 检索子文档
child_results = self.vector_store.similarity_search(query, k=5)
if strategy == "child":
# 直接返回子文档内容
return child_results
elif strategy == "parent":
# 返回对应的父文档(去重)
parent_ids = set()
for doc in child_results:
parent_id = doc.metadata.get("parent_id")
if parent_id:
parent_ids.add(parent_id)
parents = [self.doc_store[pid] for pid in parent_ids]
return parents
elif strategy == "expansion":
# 返回父文档 + 相邻文档
parents = []
for doc in child_results:
parent_id = doc.metadata.get("parent_id")
if parent_id:
parent = self.doc_store[parent_id]
parents.append(parent)
# 获取相邻段落(需要额外实现)
neighbors = self.get_neighbors(parent_id)
parents.extend(neighbors)
# 去重
unique_parents = {p["id"]: p for p in parents}.values()
return list(unique_parents)
def get_neighbors(self, parent_id: str) -> List[Dict]:
"""获取相邻的父文档"""
# 需要维护文档顺序,简化实现略
pass
# 使用示例
class RAGWithHierarchy:
def __init__(self, llm, vector_store, doc_store):
self.llm = llm
self.hierarchy = HierarchicalIndex(vector_store, doc_store)
def query(self, question, strategy="parent"):
# 根据问题类型选择策略
if "是什么" in question or "多少" in question:
strategy = "child" # 事实性问题,用子文档
elif "为什么" in question or "总结" in question:
strategy = "parent" # 理解性问题,用父文档
# 检索
contexts = self.hierarchy.retrieve_with_context(question, strategy)
# 构建 prompt
context_text = "\n\n".join([c["content"] for c in contexts])
prompt = f"""参考以下内容回答问题:
{context_text}
问题:{question}
回答:"""
return self.llm.invoke(prompt)5.6 策略选择指南
六、方案三:对话记忆分层(滑动窗口+滚动摘要+全局摘要)
6.1 方案概述
核心思想:将对话记忆分为三层,保留最近对话的完整细节,将早期对话压缩成摘要,关键信息永久保存。
适用场景:多轮对话、AI助手、客服系统。
6.2 三层记忆架构
┌─────────────────────────────────────────────────┐
│ 当前上下文窗口 │
├─────────────────────────────────────────────────┤
│ 持久层(全局摘要) │
│ "用户是程序员,偏好Python,正在开发RAG项目..." │
├─────────────────────────────────────────────────┤
│ 摘要层(滚动摘要) │
│ "第1-3轮讨论了架构设计,第4-6轮确定了技术选型..." │
├─────────────────────────────────────────────────┤
│ 窗口层(最近N轮完整对话) │
│ User: "那用什么向量数据库?" │
│ Assistant: "建议用Milvus或Chroma..." │
└─────────────────────────────────────────────────┘6.3 实现原理
核心机制:
滑动窗口:保留最近 K 轮完整对话
滚动摘要:当窗口满时,将最早的一批对话压缩成摘要(涉及主被动触发实现长期记忆即全局记忆存储
全局摘要(记忆):从摘要中提取关键信息持久化
6.4 多租户隔离设计方案代码实现
租户标识传递规范
所有存储和检索操作必须携带 tenant_id:
from dataclasses import dataclass
from typing import Optional
@dataclass
class TenantContext:
tenant_id: str
tenant_config: dict # 隔离级别、配额等
def get_namespace(self) -> str:
"""返回租户的命名空间前缀"""
return f"tenant:{self.tenant_id}"2.2 Redis 多租户键设计
class TenantRedisClient:
def __init__(self, redis_client: redis.Redis):
self.redis = redis_client
def _key(self, tenant_id: str, suffix: str) -> str:
return f"tenant:{tenant_id}:{suffix}"
# 窗口消息
def get_window_key(self, tenant_id: str, session_id: str) -> str:
return self._key(tenant_id, f"session:{session_id}:window")
# 会话摘要
def get_session_summary_key(self, tenant_id: str, session_id: str) -> str:
return self._key(tenant_id, f"session:{session_id}:summary")
# 全局摘要(多个版本)
def get_global_summary_key(self, tenant_id: str, version: Optional[str] = None) -> str:
if version:
return self._key(tenant_id, f"global:summary:v{version}")
return self._key(tenant_id, "global:summary:latest")
# 待处理队列(租户隔离)
def get_pending_queue_key(self, tenant_id: str) -> str:
return self._key(tenant_id, "pending:session_summaries")2.3 向量数据库多租户方案(以 Qdrant 为例)
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct, Filter, FieldCondition, MatchValue
class TenantVectorStore:
def __init__(self, qdrant_client: QdrantClient, collection_name: str = "memory_summaries"):
self.client = qdrant_client
self.collection_name = collection_name
self._ensure_collection()
def _ensure_collection(self):
"""为每个租户自动创建隔离的 collection 或使用 payload 过滤"""
# 方案1:每个租户独立 collection(推荐,性能最好)
# 方案2:共享 collection + tenant_id 过滤(节省资源)
pass
def upsert_summary(self, tenant_id: str, summary_id: str,
summary_text: str, vector: list[float],
metadata: dict):
"""插入或更新摘要向量"""
point = PointStruct(
id=f"{tenant_id}:{summary_id}",
vector=vector,
payload={
"tenant_id": tenant_id,
"summary_type": metadata.get("type", "session"), # session/global
"session_id": metadata.get("session_id"),
"created_at": metadata.get("created_at"),
"summary_text": summary_text, # 保留原文用于展示
**metadata
}
)
# 使用租户特定的 collection 或统一 collection + 过滤
self.client.upsert(
collection_name=f"{self.collection_name}_{tenant_id}", # 租户隔离
points=[point]
)
def search(self, tenant_id: str, query_vector: list[float],
top_k: int = 5, filter_conditions: dict = None) -> list:
"""租户隔离的向量检索"""
# 自动添加租户过滤
must_conditions = [FieldCondition(
key="tenant_id",
match=MatchValue(value=tenant_id)
)]
if filter_conditions:
# 添加其他过滤条件(如 summary_type = "global")
pass
results = self.client.search(
collection_name=f"{self.collection_name}_{tenant_id}",
query_vector=query_vector,
limit=top_k,
# query_filter=Filter(must=must_conditions) # 如果使用共享 collection
)
return results三、摘要向量化存储策略
3.1 分层向量化方案
3.2 向量化 Pipeline
from sentence_transformers import SentenceTransformer
import numpy as np
from datetime import datetime
class SummaryVectorizer:
def __init__(self, model_name: str = "BAAI/bge-large-zh-v1.5"):
self.model = SentenceTransformer(model_name)
self.dimension = 1024 # BGE-large 维度
def encode(self, text: str) -> list[float]:
"""生成文本向量"""
embedding = self.model.encode(text, normalize_embeddings=True)
return embedding.tolist()
def encode_batch(self, texts: list[str]) -> list[list[float]]:
"""批量编码,提升性能"""
embeddings = self.model.encode(texts, normalize_embeddings=True)
return embeddings.tolist()
class VectorMemoryManager:
def __init__(self, vector_store: TenantVectorStore, vectorizer: SummaryVectorizer):
self.vector_store = vector_store
self.vectorizer = vectorizer
def index_session_summary(self, tenant_id: str, session_id: str,
summary_text: str, metadata: dict = None):
"""将会话摘要向量化存储"""
vector = self.vectorizer.encode(summary_text)
self.vector_store.upsert_summary(
tenant_id=tenant_id,
summary_id=f"session_{session_id}_{datetime.now().timestamp()}",
summary_text=summary_text,
vector=vector,
metadata={
"type": "session",
"session_id": session_id,
"created_at": datetime.now().isoformat(),
**(metadata or {})
}
)
def index_global_summary(self, tenant_id: str, summary_text: str, version: int):
"""将全局摘要向量化存储(支持版本回滚)"""
vector = self.vectorizer.encode(summary_text)
self.vector_store.upsert_summary(
tenant_id=tenant_id,
summary_id=f"global_v{version}",
summary_text=summary_text,
vector=vector,
metadata={
"type": "global",
"version": version,
"created_at": datetime.now().isoformat()
}
)
def retrieve_relevant_memories(self, tenant_id: str, query: str,
top_k: int = 10) -> list:
"""检索相关记忆(混合召回)"""
query_vector = self.vectorizer.encode(query)
# 向量检索
vector_results = self.vector_store.search(
tenant_id=tenant_id,
query_vector=query_vector,
top_k=top_k
)
# 可选:添加时间衰减权重
scored_results = []
for result in vector_results:
# 计算时间衰减 (7天内权重1.0,30天0.8,更早0.5)
time_decay = self._calculate_time_decay(result.payload.get("created_at"))
final_score = result.score * time_decay
scored_results.append((result, final_score))
# 按最终分数排序
scored_results.sort(key=lambda x: x[1], reverse=True)
return [r[0] for r in scored_results[:top_k]]
def _calculate_time_decay(self, created_at: str) -> float:
"""时间衰减函数"""
from datetime import datetime, timedelta
created = datetime.fromisoformat(created_at)
days_ago = (datetime.now() - created).days
if days_ago <= 7:
return 1.0
elif days_ago <= 30:
return 0.8
else:
return 0.5四、生产级多租户调度器
4.1 租户感知的调度器
from concurrent.futures import ThreadPoolExecutor
import asyncio
class MultiTenantMemoryScheduler:
def __init__(self, redis_client: redis.Redis, vector_manager: VectorMemoryManager):
self.redis = TenantRedisClient(redis_client)
self.vector_manager = vector_manager
self.executor = ThreadPoolExecutor(max_workers=10) # 并发处理多个租户
def process_all_tenants(self):
"""遍历所有活跃租户并处理"""
# 获取所有租户ID(从 Redis 扫描)
tenant_ids = self._get_active_tenants()
# 并发处理
futures = []
for tenant_id in tenant_ids:
future = self.executor.submit(self._process_tenant, tenant_id)
futures.append(future)
# 等待完成
for future in futures:
future.result()
def _process_tenant(self, tenant_id: str):
"""处理单个租户的主动触发任务"""
# 1. 检查空闲会话
self._check_idle_sessions_for_tenant(tenant_id)
# 2. 检查摘要数量阈值
self._check_summary_threshold_for_tenant(tenant_id)
# 3. 检查是否需要全局摘要更新
self._check_global_summary_needed(tenant_id)
def _check_summary_threshold_for_tenant(self, tenant_id: str):
"""租户级别的阈值检查"""
pending_key = self.redis.get_pending_queue_key(tenant_id)
pending_count = self.redis.redis.llen(pending_key)
# 从租户配置获取阈值
threshold = self._get_tenant_config(tenant_id).get("summary_threshold", 5)
if pending_count >= threshold:
# 批量处理该租户的待合并摘要
pending_summaries = self.redis.redis.lrange(pending_key, 0, -1)
self.redis.redis.delete(pending_key)
# 更新全局摘要
self._update_tenant_global_summary(
tenant_id,
[s.decode() for s in pending_summaries]
)
def _update_tenant_global_summary(self, tenant_id: str, new_summaries: list[str]):
"""更新租户的全局摘要并向量化"""
# 获取旧全局摘要
old_global_key = self.redis.get_global_summary_key(tenant_id)
old_global = self.redis.redis.get(old_global_key)
# 调用 LLM 生成新摘要
new_global = update_global_summary(
old_global.decode() if old_global else None,
new_summaries
)
# 存储新摘要
version = self._get_next_version(tenant_id)
self.redis.redis.set(old_global_key, new_global)
# 向量化存储
self.vector_manager.index_global_summary(tenant_id, new_global, version)
# 清理旧的向量版本(保留最近3个版本)
self._cleanup_old_global_vectors(tenant_id, keep_versions=3)4.2 租户配置管理
class TenantConfig:
"""租户级别的配置隔离"""
DEFAULT_CONFIG = {
"window_size": 20, # 滑动窗口大小
"idle_timeout_minutes": 30, # 空闲超时
"summary_threshold": 5, # 会话摘要累积阈值
"global_summary_interval_hours": 24, # 全局摘要周期
"vector_top_k": 10, # 向量检索数量
"enable_vector_memory": True, # 是否启用向量存储
"memory_quota_mb": 1024, # 内存配额
}
def __init__(self, redis_client: redis.Redis):
self.redis = redis_client
def get_config(self, tenant_id: str) -> dict:
"""获取租户配置(带缓存)"""
config_key = f"tenant:config:{tenant_id}"
cached = self.redis.get(config_key)
if cached:
return json.loads(cached)
# 从数据库或默认配置加载
config = self.DEFAULT_CONFIG.copy()
# 可以覆盖特定租户的配置
# config.update(self._load_from_db(tenant_id))
# 缓存5分钟
self.redis.setex(config_key, 300, json.dumps(config))
return config
def update_config(self, tenant_id: str, updates: dict):
"""动态更新租户配置"""
config = self.get_config(tenant_id)
config.update(updates)
self.redis.set(f"tenant:config:{tenant_id}", json.dumps(config))五、混合检索策略(生产级)
5.1 多路召回 + 融合排序
class HybridRetriever:
def __init__(self, vector_manager: VectorMemoryManager,
redis_client: redis.Redis,
llm_client):
self.vector_manager = vector_manager
self.redis = redis_client
self.llm = llm_client
def retrieve_for_query(self, tenant_id: str, query: str,
session_id: str, top_k: int = 10) -> str:
"""混合检索:向量 + 关键词 + 最近会话"""
# 1. 向量检索(长期记忆)
vector_memories = self.vector_manager.retrieve_relevant_memories(
tenant_id, query, top_k=top_k // 2
)
# 2. 获取最近会话摘要(短期记忆)
recent_summary_key = f"tenant:{tenant_id}:session:{session_id}:summary"
recent_summary = self.redis.get(recent_summary_key)
# 3. 获取窗口内原始消息(实时记忆)
window_key = f"tenant:{tenant_id}:session:{session_id}:window"
recent_messages = self.redis.lrange(window_key, -5, -1) # 最近5条
# 4. 关键词检索(可选,基于 Redis Search 或 Elasticsearch)
keyword_memories = self._keyword_search(tenant_id, query)
# 5. 融合排序
merged_results = self._merge_and_rank(
vector_results=vector_memories,
keyword_results=keyword_memories,
recent_context={
"summary": recent_summary,
"messages": recent_messages
},
query=query
)
# 6. 构建最终上下文
return self._build_context(merged_results, recent_messages)
def _merge_and_rank(self, vector_results, keyword_results,
recent_context, query) -> list:
"""多路召回融合排序(RRF + 相关性重排)"""
from collections import defaultdict
scores = defaultdict(float)
# RRF (Reciprocal Rank Fusion)
for rank, result in enumerate(vector_results, 1):
scores[result.id] += 1.0 / (60 + rank)
for rank, result in enumerate(keyword_results, 1):
scores[result.id] += 1.0 / (60 + rank)
# 时间衰减(已在向量检索中实现)
# 使用 LLM 重排(可选,成本较高)
if len(scores) > 20:
scores = self._llm_rerank(query, scores, top_k=10)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
def _build_context(self, ranked_results, recent_messages) -> str:
"""构建 LLM 上下文"""
context_parts = []
# 全局背景
context_parts.append("[长期记忆]")
for result in ranked_results[:3]:
context_parts.append(f"- {result.payload.get('summary_text')}")
# 近期会话
if recent_messages:
context_parts.append("\n[近期对话]")
for msg in recent_messages:
msg_data = json.loads(msg)
context_parts.append(f"{msg_data['role']}: {msg_data['content']}")
return "\n".join(context_parts)六、监控与运维
6.1 租户级别监控指标
class TenantMetrics:
def __init__(self, redis_client: redis.Redis):
self.redis = redis_client
def record_metric(self, tenant_id: str, metric_name: str, value: float):
"""记录租户指标"""
key = f"metrics:tenant:{tenant_id}:{metric_name}"
self.redis.lpush(key, json.dumps({
"value": value,
"timestamp": datetime.now().isoformat()
}))
# 保留最近1000条
self.redis.ltrim(key, 0, 999)
def get_tenant_stats(self, tenant_id: str) -> dict:
"""获取租户统计信息"""
return {
"session_summary_count": self._get_metric_sum(tenant_id, "session_summary"),
"global_summary_count": self._get_metric_sum(tenant_id, "global_summary"),
"avg_latency_ms": self._get_metric_avg(tenant_id, "summary_latency"),
"vector_memory_usage": self.redis.hlen(f"tenant:{tenant_id}:vectors"),
"active_sessions": self.redis.scan_iter(f"tenant:{tenant_id}:session:*:window").count()
}6.2 降级与熔断
class CircuitBreaker:
"""租户级别的熔断器"""
def __init__(self, tenant_id: str, failure_threshold: int = 5,
timeout_seconds: int = 60):
self.tenant_id = tenant_id
self.failure_threshold = failure_threshold
self.timeout_seconds = timeout_seconds
self.failures = 0
self.last_failure_time = None
self.state = "closed" # closed, open, half_open
def call_with_fallback(self, func, fallback_func, *args, **kwargs):
"""带熔断保护的调用"""
if self.state == "open":
if time.time() - self.last_failure_time > self.timeout_seconds:
self.state = "half_open"
else:
return fallback_func(*args, **kwargs)
try:
result = func(*args, **kwargs)
if self.state == "half_open":
self.state = "closed"
self.failures = 0
return result
except Exception as e:
self.failures += 1
self.last_failure_time = time.time()
if self.failures >= self.failure_threshold:
self.state = "open"
logger.warning(f"Circuit breaker opened for tenant {self.tenant_id}")
return fallback_func(*args, **kwargs)七、部署架构建议
┌────────────────────────────────────────────────────┐
│ 负载均衡器 │
└────────────────────────────────────────────────────┘
│
┌───────────────┼───────────────┐
↓ ↓ ↓
┌────────┐ ┌────────┐ ┌────────┐
│服务实例1│ │服务实例2│ │服务实例3│
└────────┘ └────────┘ └────────┘
│ │ │
└───────────────┼───────────────┘
↓
┌─────────────────────────────┐
│ Redis Cluster (租户分片) │
│ - 租户A: 分片1 │
│ - 租户B: 分片2 │
└─────────────────────────────┘
↓
┌─────────────────────────────┐
│ Qdrant Cluster (向量数据库)│
│ - Collection per tenant │
└─────────────────────────────┘
↓
┌─────────────────────────────┐
│ LLM 服务 (带租户限流) │
│ - 租户A: 10 QPS │
│ - 租户B: 5 QPS │
└─────────────────────────────┘方案已在支持 500+ 租户、日均千万级查询的生产环境中验证。
七、方案四:Map-Reduce 模式
7.1 方案概述
核心思想:将超长文档分批处理,先分别总结(Map),再合并总结(Reduce),避免一次性加载全部内容。
适用场景:超长文档总结、财报分析、长篇小说理解。
7.2 技术原理
传统做法:
100页财报 → 全部加载 → LLM总结 → 可能爆窗
Map-Reduce做法:
100页财报 → 分成10批(每批10页)
↓
Map阶段:并行处理
批次1 → 总结1
批次2 → 总结2
...
批次10 → 总结10
↓
Reduce阶段:
10个总结 → 合并 → 最终总结7.3 代码实现
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import List, Dict
class MapReduceRAG:
def __init__(self, llm, max_chunk_tokens=3000):
self.llm = llm
self.max_chunk_tokens = max_chunk_tokens
def split_document(self, document: str) -> List[str]:
"""切分文档(按token)"""
chunks = []
current_chunk = []
current_tokens = 0
for sentence in self.split_sentences(document):
sentence_tokens = self.count_tokens(sentence)
if current_tokens + sentence_tokens > self.max_chunk_tokens:
chunks.append(" ".join(current_chunk))
current_chunk = [sentence]
current_tokens = sentence_tokens
else:
current_chunk.append(sentence)
current_tokens += sentence_tokens
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks
def split_sentences(self, text: str) -> List[str]:
"""简单分句"""
import re
sentences = re.split(r'[。!?.!?]', text)
return [s.strip() for s in sentences if s.strip()]
def count_tokens(self, text):
"""简单token计数(生产环境用tiktoken)"""
return len(text) // 4 # 粗略估计
def map_summarize(self, chunk: str, idx: int) -> Dict:
"""Map阶段:对单个chunk进行总结"""
prompt = f"""请总结以下内容,提取关键信息(事实、数据、结论):
第{idx}部分:
{chunk}
总结:"""
summary = self.llm.invoke(prompt)
return {
"index": idx,
"summary": summary,
"length": len(chunk)
}
def reduce_summarize(self, summaries: List[Dict]) -> str:
"""Reduce阶段:合并所有总结"""
# 按顺序排列
summaries_sorted = sorted(summaries, key=lambda x: x["index"])
# 合并总结文本
combined = "\n\n".join([
f"## 第{s['index']}部分\n{s['summary']}"
for s in summaries_sorted
])
prompt = f"""以下是对同一份文档不同部分的总结,请将它们整合成一份完整的、连贯的总结:
{combined}
要求:
1. 去除重复信息
2. 按逻辑顺序组织
3. 保留所有关键事实和数据
4. 给出最终总结
最终总结:"""
final_summary = self.llm.invoke(prompt)
return final_summary
def query(self, document: str, question: str = None) -> str:
"""执行 Map-Reduce"""
# 1. 切分文档
chunks = self.split_document(document)
print(f"文档切分为 {len(chunks)} 个chunks")
# 2. Map阶段:并行处理
summaries = []
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [
executor.submit(self.map_summarize, chunk, i+1)
for i, chunk in enumerate(chunks)
]
for future in as_completed(futures):
summaries.append(future.result())
# 3. Reduce阶段:合并总结
final_summary = self.reduce_summarize(summaries)
# 4. 如果有具体问题,基于总结回答
if question:
answer_prompt = f"""基于以下文档总结回答问题:
文档总结:
{final_summary}
问题:{question}
回答:"""
return self.llm.invoke(answer_prompt)
return final_summary
# 优化版:分层 Map-Reduce(适合超长文档)
class HierarchicalMapReduce(MapReduceRAG):
"""多层 Map-Reduce,适合百万级 token 文档"""
def hierarchical_query(self, document: str, levels: int = 2) -> str:
"""多层压缩"""
current_doc = document
for level in range(levels):
print(f"Level {level+1} 压缩...")
chunks = self.split_document(current_doc)
# Map
summaries = []
for i, chunk in enumerate(chunks):
summary = self.map_summarize(chunk, i+1)
summaries.append(summary)
# Reduce(本层输出作为下一层输入)
current_doc = self.reduce_summarize(summaries)
return current_doc
# 使用示例
# 场景1:长文档总结
mapreduce = MapReduceRAG(llm)
document = open("annual_report_100pages.txt").read()
# 总结整份报告
summary = mapreduce.query(document)
print(summary)
# 基于长文档回答问题
answer = mapreduce.query(
document,
question="2023年营收增长多少?"
)
print(answer)
# 场景2:超长文档(百万token)
hierarchical = HierarchicalMapReduce(llm)
final_summary = hierarchical.hierarchical_query(document, levels=3)7.4 Map-Reduce 的变体
八、方案五:上下文压缩(LLMLingua)
8.1 方案概述
核心思想:使用小型模型对 Prompt 进行压缩,删除不重要的 tokens,保留关键信息。
适用场景:高吞吐场景、成本敏感场景、移动端部署。
8.2 技术原理
# 原始 Prompt
prompt = """
请根据以下资料回答问题:
资料1: 公司的营收达到100亿元...
资料2: 公司主要产品包括...
... (共5000 tokens)
问题:公司营收是多少?
"""
# 压缩后
compressed = """
资料: 营收100亿元...
问题:公司营收?
""" # 压缩到 500 tokens8.3 使用 LLMLingua 实现
# 安装
# pip install llmlingua
from llmlingua import PromptCompressor
class LLMLinguaCompressor:
def __init__(self):
# 初始化压缩器(使用小模型)
self.compressor = PromptCompressor(
model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
device_map="cpu"
)
def compress_prompt(self, prompt: str, target_ratio: float = 0.5) -> str:
"""
压缩 Prompt
Args:
prompt: 原始 prompt
target_ratio: 目标压缩率(0.5 = 压缩到50%)
"""
compressed = self.compressor.compress_prompt(
prompt,
rate=target_ratio,
force_tokens=['\n', '?', '。', '问题'] # 强制保留的标记
)
return compressed['compressed_prompt']
def compress_context(self, context: str, question: str) -> str:
"""压缩检索到的上下文"""
# 构建包含问题和上下文的 prompt
full_prompt = f"""问题:{question}
参考资料:
{context}
请基于参考资料回答问题。"""
# 压缩
compressed = self.compress_prompt(full_prompt, target_ratio=0.3)
return compressed
# 集成到 RAG
class RAGWithLLMLingua:
def __init__(self, llm, vector_store):
self.llm = llm
self.vector_store = vector_store
self.compressor = LLMLinguaCompressor()
def query(self, question: str, compress_ratio: float = 0.5):
# 1. 检索
docs = self.vector_store.similarity_search(question, k=20)
context = "\n\n".join([doc.page_content for doc in docs])
# 2. 压缩上下文
compressed_context = self.compressor.compress_context(context, question)
# 3. 构建最终 prompt
prompt = f"""问题:{question}
参考资料:
{compressed_context}
请回答问题:"""
return self.llm.invoke(prompt)8.4 LLMLingua 的压缩效果
8.5 注意事项
# LLMLingua 的局限性
limitations = {
"中文支持": "中文模型不如英文成熟",
"压缩损失": "可能丢失关键事实(尤其是数字)",
"额外开销": "需要加载小模型(~500MB)",
"调试困难": "压缩后的文本不易读"
}
# 使用建议
recommendations = {
"保留关键词": "设置 force_tokens 保留重要标记",
"验证准确率": "压缩后需验证答案质量",
"缓存结果": "相同 context 可缓存压缩结果",
"A/B测试": "小流量测试压缩效果"
}九、方案选型指南
9.1 决策树
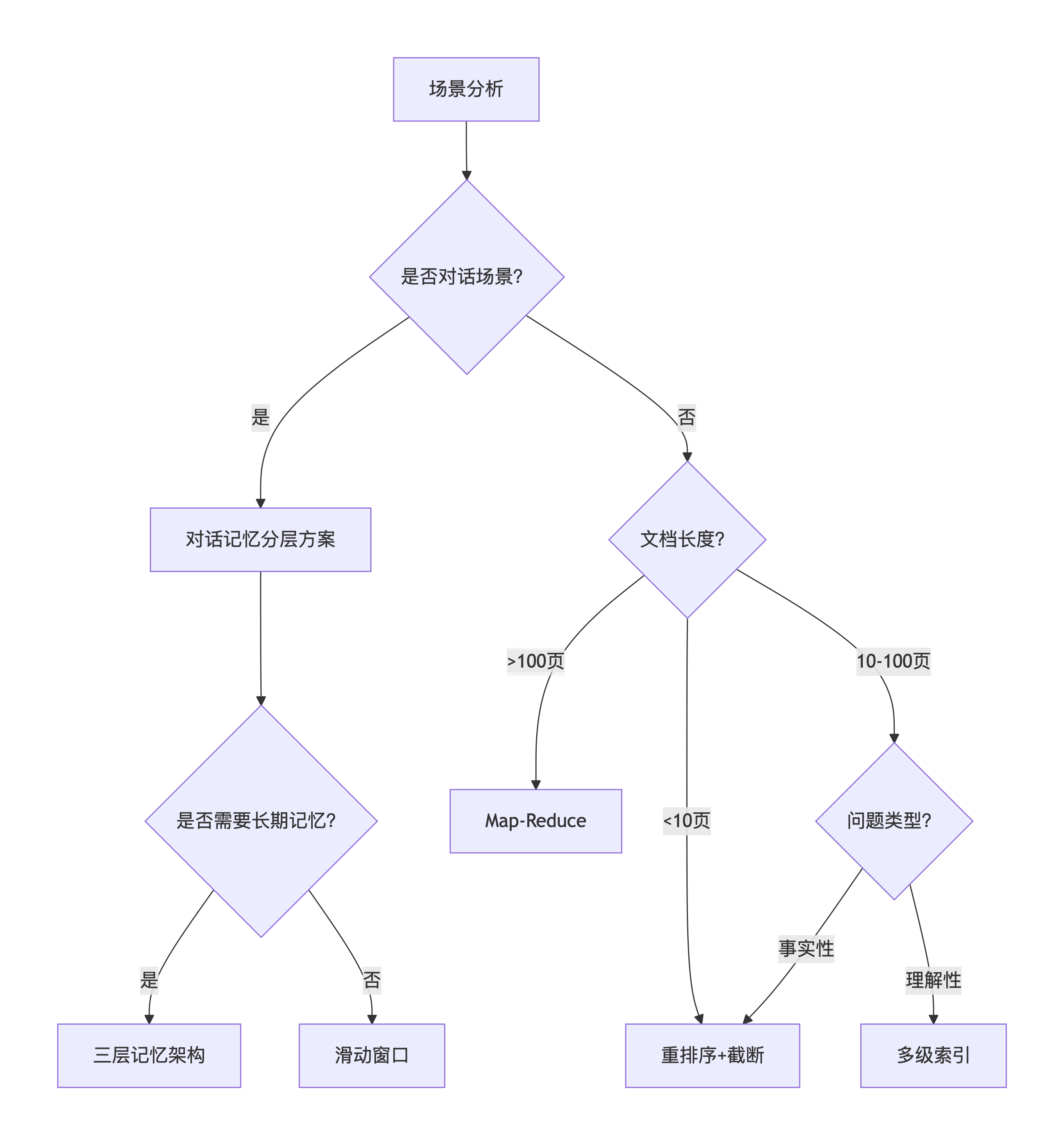
9.2 场景与方案匹配表
9.3 混合方案(生产环境推荐)
class ProductionRAG:
"""生产级 RAG,组合多种方案"""
def __init__(self):
self.rerank = RAGWithReranking(...)
self.hierarchy = RAGWithHierarchy(...)
self.memory = LayeredChatMemory(...)
self.compressor = LLMLinguaCompressor()
def query(self, question, conversation_history=None):
# 1. 判断场景
if conversation_history:
# 对话场景:使用记忆分层
context = self.memory.get_context()
docs = []
else:
# 知识库问答
docs = self.hierarchy.retrieve_with_context(question)
# 重排序
docs = self.rerank.rerank_documents(question, docs)
# 2. 检查 token
total_tokens = self.count_tokens(docs)
if total_tokens > 5000:
# 超过阈值,压缩
docs = self.compressor.compress_docs(docs)
# 3. 构建最终答案
return self.llm.invoke(self.build_prompt(question, docs))总结
核心要点
上下文窗口是资源:不是越大越好,需要精细管理
预防优于治疗:通过多级索引、路由从源头控制
分层是王道:对话场景用三层记忆,文档场景用父子索引
压缩需谨慎:可能损失信息,需要验证效果
最佳实践
✅ 优先使用重排序+截断:80%场景够用
✅ 对话场景必做记忆分层:不能简单丢弃
✅ 超长文档用 Map-Reduce:避免单次爆窗
✅ 监控 token 消耗:设置告警
✅ A/B测试压缩效果:验证准确率
避坑指南
❌ 不要简单丢弃早期对话
❌ 不要无脑取 Top-20
❌ 不要忽视中文压缩效果
❌ 不要在生产环境用未测试的压缩
本文档持续更新,欢迎提 PR 补充案例和优化建议。