

知识图谱完全指南:从入门思想到Neo4j/Cypher工业实战
写在前面
这是一篇真正从零开始的知识图谱系统介绍。
我不会假设你已经懂了什么,也不会把概念堆砌成字典。整篇文章沿着一条逻辑主线展开:我们为什么需要知识图谱 → 它由什么构成 → 如何从原始数据中抽取知识 → 怎样存储和查询 → 最终如何落地。
你将在这篇文章里看到:
✅ 知识图谱的核心思想与概念辨析
✅ 实体抽取的BIO/BIEO/IO标注体系完整讲解
✅ Neo4j图数据库与Cypher查询语言实战
✅ 从文本到图谱的完整构建流水线
✅ 工业界真实踩坑经验与学习路径建议
一、概念思想篇——知识图谱不是什么,是什么
1.1 一个思想实验
假设你在用传统数据库查询:“姚明效力过的球队的主场在哪个城市?”
SQL需要这样写:
SELECT city.name
FROM person
JOIN play_contract ON person.id = play_contract.person_id
JOIN team ON play_contract.team_id = team.id
JOIN located ON team.id = located.team_id
JOIN city ON located.city_id = city.id
WHERE person.name = '姚明'四张表联查,性能随关联深度指数下降。如果你突然想查“姚明队友的主场城市”,需要再联一张表。
知识图谱的解法:
你只需要沿着图走:姚明 → [效力于] → 球队 → [位于] → 城市
这不是语法糖,而是思维范式的转换:从“表连接”到“图遍历”,从“精确匹配”到“语义关联”。
1.2 知识图谱的数学定义
知识图谱在数学上是一个异构图:
G = (E, R, F)
E:实体集合(节点),如姚明、休斯顿火箭、上海
R:关系集合(边),如效力于、出生于、位于
F:事实集合(三元组),形式为 (头实体, 关系, 尾实体)
(姚明, 效力于, 休斯顿火箭)
(休斯顿火箭, 位于, 休斯顿)
1.3 知识图谱不是什么——给初学者的三个认知纠偏
❌ 误区一:知识图谱 = 图数据库
Neo4j、JanusGraph是载体,不是本质。你用Excel画一个节点连线图,那也是知识图谱——只是不好查询而已。
❌ 误区二:知识图谱全靠NLP从文本里抽
工业界真实分布:
70% 知识来自结构化数据(数据库表、Excel)
20% 来自半结构化数据(JSON、XML、网页表格)
10% 来自纯文本(新闻、文档)
❌ 误区三:知识图谱要“抽完所有知识”
好的知识图谱是克制的。只抽取当前业务需要的实体和关系,比追求“大而全”更重要。
二、基本结构:结构篇——知识图谱的双层架构
任何一个可工作的知识图谱,都包含两个层次:
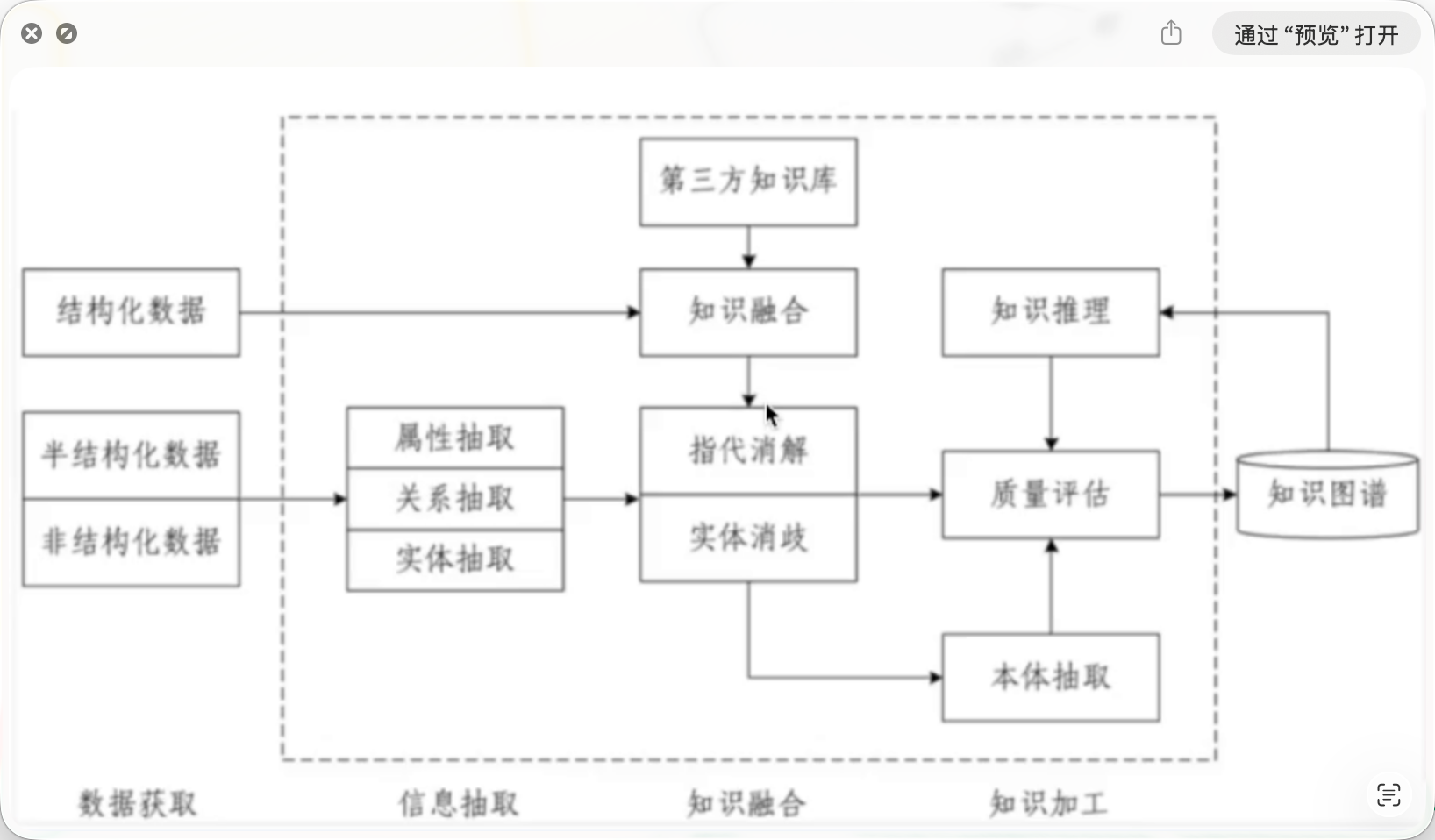
2.1 模式层(Schema Layer)
这是知识图谱的骨架,相当于面向对象编程里的类定义。
实体类型:人(Person)、球队(Team)、城市(City)
关系类型:效力于(PLAY_FOR)、出生于(BORN_IN)、位于(LOCATED_IN)
属性约束:人的出生年份必须是整数,且 ≤ 当前年份在技术实现上,模式层可以用本体(Ontology)严格定义(如OWL语言),也可以在Neo4j里用节点标签(Label)隐式约定。对于初学者,从隐式约定开始,不要上来就陷入本体工程的泥潭。
2.2 数据层(Data Layer)
这是知识图谱的血肉,是具体的实例:
text
(:Person {name: "姚明", birth: 1980})
(:Team {name: "休斯顿火箭", founded: 1967})
(:City {name: "休斯顿", country: "美国"})
(姚明)-[:PLAY_FOR {from: 2002, to: 2011}]->(休斯顿火箭)
(休斯顿火箭)-[:LOCATED_IN]->(休斯顿)关键理解:模式层是“类”,数据层是“对象”。先有类还是先有对象?在工程上都可以,但建议先设计简单的模式层再灌数据,否则后面会陷入实体类型不一致的泥潭。
三、抽取篇——从非结构化文本到结构化知识
这是NLP领域最核心、也最让初学者头疼的部分。我们拆开揉碎来讲。
3.1 实体抽取:序列标注与三大标注体系
实体抽取(Named Entity Recognition, NER)的任务是:给定一句话,把其中的命名实体边界和类型找出来。
问题形式化
输入:[姚, 明, 是, 中, 国, 人]
输出:[PER, PER, O, LOC, LOC, O]
这是一个序列标注问题,我们需要为每个token打一个标签。
标注体系详解
1. IO体系(最原始)
text
姚/I-PER 明/I-PER 是/O 中/I-LOC 国/I-LOC 人/O❌ 致命缺陷:无法区分相邻同类型实体。
“李明李明来找你” → I-PER I-PER I-PER I-PER,这是一个人叫“李明李明”,还是两个人“李明”和“李明”?机器无法知道。
2. BIO体系(工业界绝对主流)
姚/B-PER 明/I-PER 是/O 中/B-LOC 国/I-LOC 人/O✅ 优势:明确了实体的起始边界,解决了相邻实体区分问题。
3. BIEO/BIOES体系(精细控制)
姚/B-PER 明/E-PER 是/O 中/S-LOC 国/S-LOC 人/O✅ 优势:
边界定位极其精准
单字实体用S标记,避免B/I/E无法覆盖单字的情况
中文分词不准确时,这种字级别的精细标注鲁棒性更强
技术演进路线
词典匹配(1980s)
↓
CRF(2001) —— 需要人工设计特征模板
↓
BiLSTM-CRF(2015) —— 自动提取特征,特征工程→特征学习
↓
BERT(2018) —— 预训练+微调,横扫各大榜单
↓
FLAT/GlobalPointer(2021) —— 非序列化建模,解决长距离依赖工业界现状:通用领域BERT-base NER F1值约92-95%,垂直领域(医疗、法律、金融)标注数据稀缺时,通常在80-85%之间挣扎。
3.2 关系抽取:从管道到联合学习
实体抽取只是找到了“有哪些概念”,关系抽取要回答“它们之间是什么关系”。
管道式抽取(Pipeline)
文本 → NER → 实体候选 → 两两组合 → 关系分类 → 三元组⚠️ 问题:误差传播。NER漏掉实体,关系就100%错;NER错标边界,关系特征就乱掉。此外,$n$个实体产生$C(n,2)$个候选对,算力浪费严重。
联合抽取(Joint Extraction)
核心思想:实体和关系不是先后步骤,而是共同决策。
主流范式:
1. 参数共享:一个BERT编码层,上面接两个任务头(NER头、关系分类头),共享上下文表征。
2. 生成式抽取:如Seq2Seq,直接把文本翻译成三元组序列。
输入:姚明效力于休斯顿火箭
输出:(姚明, 效力于, 休斯顿火箭)
3. 握手标注:如TPLinker、CasRel。将关系抽取转化为指针网络,头实体的尾位置指向尾实体的头位置,像两只手握在一起。
工业界忠告
不要指望纯NLP抽取达到100%精度。天花板就在那里(约85-90% F1)。可靠的图谱必须引入人工规则、知识库约束、事后校验。
四、存储与查询篇——Neo4j + Cypher实战
有了三元组,怎么存、怎么查?
4.1 为什么是Neo4j?
市面上图数据库很多,Neo4j是工业界认知度最高、学习曲线最平缓的选择。
核心优势:
属性图模型(Property Graph)
节点可以有多个标签(Label),类似“多重继承”
关系必须有方向、类型、也可以有属性
比RDF三元组更贴近开发者的直觉
原生图存储
Neo4j不是用关系型数据库模拟图,而是真正的图存储。节点物理上存着指向邻居的指针,遍历复杂度O(1),与全图规模无关。ACID事务
企业级落地的及格线。JanusGraph等HBase生态方案在事务支持上较弱。
4.2 Cypher:写给人类的图查询语言
Cypher的设计哲学是用ASCII艺术画图。
基础语法模式
(节点:标签 {属性}) - [:关系类型 {属性}] -> (节点:标签)从零开始的Cypher实战
1. 创建节点
CREATE (p:Person {name: '姚明', birth: 1980, height: 2.26})
CREATE (t:Team {name: '休斯顿火箭', founded: 1967})
CREATE (c:City {name: '休斯顿', country: '美国'})2. 创建关系
MATCH (p:Person {name: '姚明'})
MATCH (t:Team {name: '休斯顿火箭'})
CREATE (p)-[:PLAY_FOR {start: 2002, end: 2011}]->(t)
MATCH (t:Team {name: '休斯顿火箭'})
MATCH (c:City {name: '休斯顿'})
CREATE (t)-[:LOCATED_IN]->(c)3. 核心查询:多跳关联
// 问题:姚明效力过的球队的主场在哪个城市?
MATCH (p:Person {name: '姚明'})-[:PLAY_FOR]->(t:Team)
MATCH (t)-[:LOCATED_IN]->(c:City)
RETURN t.name AS 球队, c.name AS 城市
// 结果:休斯顿火箭 | 休斯顿4. 变长路径:穿透多层关系
// 问题:姚明和麦迪有什么关系?
MATCH (p1:Person {name: '姚明'})
MATCH (p2:Person {name: '特雷西·麦克格雷迪'})
MATCH path = shortestPath((p1)-[*..6]-(p2))
RETURN path
// 结果:姚明-[:PLAY_FOR]->休斯顿火箭<-[:PLAY_FOR]-麦迪5. 聚合分析
// 每个城市的球队数量
MATCH (t:Team)-[:LOCATED_IN]->(c:City)
RETURN c.name AS 城市, COUNT(t) AS 球队数量
ORDER BY 球队数量 DESCCypher vs SQL:思维转换
对于关联深度 > 2 的查询,Cypher的表达效率碾压SQL。
五、融合篇——知识图谱的“对账”工程
5.1 什么是知识融合?
你从文本A抽出“周杰伦”,文本B抽出“周董”,数据库C取出“Jay Chou”。
人知道这是同一个人,机器不知道。
知识融合的任务是:将来自不同源、指向同一真实实体的不同指称,对齐合并为全局唯一节点。
5.2 四大核心子任务
关键辨析:
共指消解是文档内任务,实体统一是跨源任务
实体消歧解决“一词多义”,实体统一解决“多词一义”
5.3 技术体系演进
第一层:符号主义(规则+特征)
属性相似度:编辑距离、Jaccard、TF-IDF
结构相似度:邻居重叠率
决策:加权投票、阈值规则
✅ 可解释,零样本 ❌ 特征工程成本高
第二层:表示学习(Embedding)
TransE:h + r ≈ t,向量空间推理
改进:TransH/TransR/RotatE
✅ 无特征工程 ❌ 难处理复杂关系,缺数据失效
第三层:图神经网络(GNN)
GCN-Align:聚合邻居结构判断等价
核心洞察:即使属性文本完全不同,邻居结构相似仍可对齐
✅ 结构鲁棒 ❌ 计算开销大,冷启动困难
第四层:大语言模型(Prompt)
转化为自然语言理解:“‘周杰伦’和‘周董’是同一个人吗?”
✅ 零样本,可推理 ❌ 成本高,延迟高,不稳定
5.4 工业界真相
论文F1刷到95%,工业界60%是常态。
三大死穴:
长尾分布
头部20%实体贡献80%上下文,尾部实体几乎没有可用信息。
论文筛选“至少有5个邻居”,工业界没有这个奢侈。数据质量灾难
“周杰倫”(繁体)、“周杰伦”(OCR错字)、“周截伦”(语音误听)
不是算法不够好,是输入不允许它好。人工审核瓶颈
审核员看不懂“为什么A=B”,速度赶不上数据增长。
可行工程策略:
ROI最高的操作:建一个高频别名强制映射表(周董→周杰伦),比调三天模型都管用。
一句话总结:知识融合不是算法竞赛,是数据工程+人机协作。承认没有银弹,才能做出落地系统。
5.5 实践建议
如果你正在做知识图谱项目,关于知识融合,记住三句话:
不要在融合阶段试图解决抽取阶段的错误。
如果NER把“新奥尔良”抽成了“奥尔良”,融合救不回来。不要相信任何宣称“全自动知识融合”的商业软件。
目前没有。未来3-5年也不会有。不要用刷论文的心态做融合。
论文关心F1值从94%提升到94.5%。
工业界关心:能不能用规则先把那20%的明显错误修掉。
可立即执行的三个动作:
收集你业务场景里的高频别名,建一个强制映射表。这是ROI最高的操作。
如果做跨语言对齐,先机器翻译再对齐,比直接跨语言嵌入更稳定。
可视化你的候选对齐结果。给审核人员看“为什么算法认为A=B”,比直接扔给他们一个决策结果,效率高3倍以上。
六、构建篇——完整流水线与工具链选择
6.1 通用构建流水线
原始数据层
↓
【结构化数据】 【半结构化】 【非结构化】
MySQL/Excel HTML/JSON PDF/文本
↓ ↓ ↓
D2RQ映射 XPath包装 NER+关系抽取
↓ ↓ ↓
└───────┬──────┘ ↓
↓ ↓
数据层实体 【待融合新实体】
↓ ↓
└─────────┬──────────┘
↓
【知识融合模块】
实体对齐、合并
↓
【知识存储层】
Neo4j/JanusGraph
↓
【上层应用层】
问答/推荐/反欺诈6.2 各环节推荐工具(亲测可用)
6.3 两种构建模式的选择
1. 自顶向下(Top-down)
先定义本体,再填充数据。
✅ 适合:领域专业库、百科类图谱
❌ 挑战:模式设计需要领域专家
2. 自底向上(Bottom-up)
先有实例,再归纳模式。
✅ 适合:探索性分析、开放域抽取
❌ 挑战:模式一致性难保证
初学者建议:先自底向上做出MVP(最小可行图谱),再迭代重构模式层。不要试图第一次就设计出完美的本体。
七、学习篇——给博客读者的成长地图
作为过来人,我知道你现在最困惑的不是某个具体技术,而是“这么多东西,我先学什么?后学什么?”
7.1 学习路径规划(3-6个月)
第一阶段:建立体感(2周)
下载Neo4j Desktop,导入
movie.cypher示例库手写20个Cypher查询,覆盖增删改查
用Python的
py2neo连接Neo4j,插入100条自己的数据
第二阶段:结构化数据转图谱(2周)
找一张Excel成绩表(学生、课程、成绩)
设计图谱模型:学生-选修-课程
用LOAD CSV导入Neo4j
目标:彻底理解“关系型→图型”的映射思维
第三阶段:非结构化抽取入门(4周)
学习HMM、CRF的基本原理(不用深究数学)
用LAC跑通中文NER
用BERT微调一个自己的NER模型(5万条标注数据量级)
第四阶段:全流程项目实战(6周)
选一个小领域(如“电影人物关系”)
爬取豆瓣/IMDb的半结构化数据
设计简单模式层
做实体对齐(IMDb vs 豆瓣)
存入Neo4j
写3个有意思的Cypher查询
7.2 学习资源推荐
书籍:
《知识图谱:方法、实践与应用》(国内团队,全面)
《Graph Databases》(Neo4j官方,案例丰富)
课程:
知网:东南大学《知识图谱》公开课(理论扎实)
B站:同济大学《图数据库与知识图谱》(动手多)
项目:
GitHub:
ownthink/KnowledgeGraph(2k星,完整代码)GitHub:
crownpku/Information-Extraction-Chinese(中文信息抽取)
7.3 最后的忠告
不要沉迷于刷论文。
知识图谱是工程属性极强的领域。很多学术论文(尤其是顶会)解决的是“标注数据充足、领域封闭、评测指标单一”的玩具问题。
你遇到的工业问题是:
标注数据只有几百条
实体类型有200+种
关系重叠嵌套
同一实体有17种别名
这些问题的解法,论文里没有,开源代码里没有,但在每个落地项目的Issue里都有。
八、相关应用场景
作为RAG系统的外在数据源增强数据与回答可靠性
解决RAG系统无法实现多条问题
作为某些app如企查查,医药-疾病等展示
结语
知识图谱不是一个“安装即运行”的软件,而是一套用图思维解构业务问题的思想。
当你面对一个复杂业务场景,不再本能地画ER图、建表、写SQL,而是开始思考“这里有几种实体、它们如何关联、用户会沿着什么路径遍历”——这时候,你才真正入了门。
这篇文章从思想萌芽写到工业落地,从BIO标注写到Cypher查询,从融合算法写到学习路线。如果它能让你少走三个月弯路,便已足够。
现在,打开Neo4j,开始你的第一条CREATE语句吧。
