

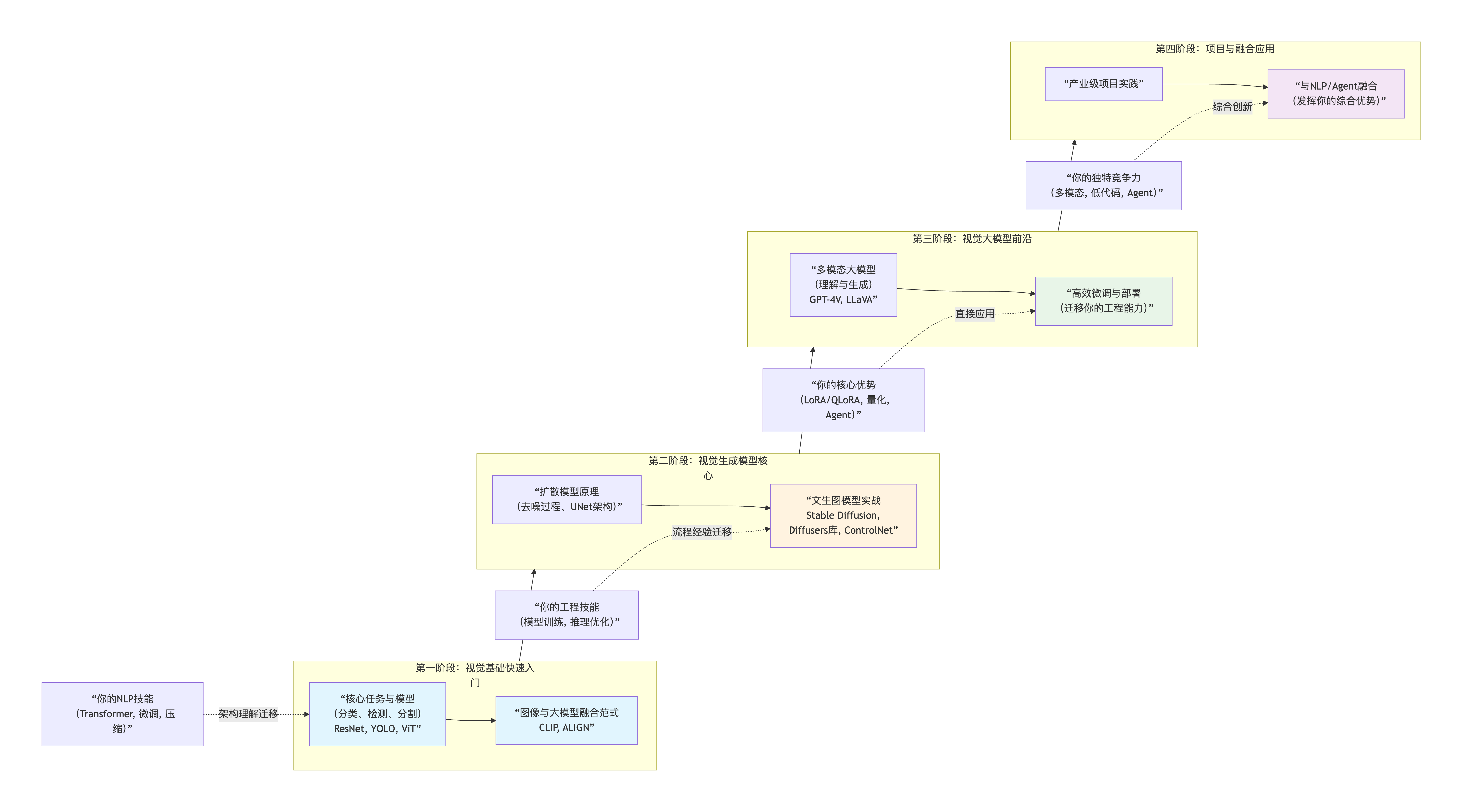
一、学习路线
二、必学模型
核心思想—览表:在深入了解细节前,你可以先快速把握它们最核心的差异:
1、ResNet
ResNet:深度学习的“高速公路”
ResNet要解决的根本问题是:网络越深,效果反而越差吗? 答案是否定的,但需要一种机制来保证。
核心问题:传统的CNN随着层数加深,会出现梯度消失/爆炸和网络退化问题。网络不是学不到,而是难以优化。
天才方案:残差块 与 快捷连接。
残差学习:不让网络直接学习目标映射
H(x),而是学习残差F(x) = H(x) - x。快捷连接:通过一条“捷径”,将输入
x直接加到经过几层卷积后的输出F(x)上,最终输出为F(x) + x。直观理解:如果更深的层学不到新东西,这个“捷径”可以轻松地将网络退化成较浅的版本,至少保证性能不下降。这使得网络可以安全地堆叠到极深(如ResNet-152有152层)。
入门建议:
重点理解残差块的结构图和公式
y = F(x, {Wi}) + x。在PyTorch中尝试调用
torchvision.models.resnet18(),看看它的层结构。应用:几乎所有视觉任务的特征提取骨干网络。
2、YOLO
YOLO:目标检测的“闪电侠”
YOLO要解决的痛点是:此前的检测模型(如R-CNN系列)速度慢、步骤多。YOLO提出了一种全新的思路。
核心思想:端到端,一次看完。
将输入图像划分为
S x S的网格。每个网格负责预测:中心落在该网格内的物体的边界框(
x, y, w, h)、置信度以及类别概率。整个检测过程只需要一次前向传播,速度可比实时(FPS > 30)。
工作流程 (以YOLOv1为例):
划分网格:将图片分成
7x7网格。每个网格预测:每个网格预测
B个边界框和C个类别概率。后处理:通过非极大值抑制(NMS)过滤掉重复和低置信度的预测框。
入门建议:
重点理解“网格预测”的直观思想。可以想象成让每个网格单元都成为一个“小检测器”。
从YOLOv5/v8入手:它们生态完善,文档友好。直接去GitHub下载 Ultralytics YOLOv8,用其预训练模型跑一下图片或视频检测,感受其速度。
记住关键改进:后续版本在骨干网络、特征金字塔(FPN)、损失函数上持续优化,但“一次看完”的核心思想未变。
3、ViT:Vision Transformer
ViT:Transformer的“视觉入侵者”
ViT要回答一个颠覆性问题:计算机视觉必须依赖CNN吗? 它用Transformer在图像分类任务上给出了否定答案。
核心思想:图像即序列。
图像分块:将一张图像切割成固定大小(如16x16像素)的图像块。
线性映射:将每个图像块展平,并通过一个线性层映射为特征向量(类似NLP中的词嵌入)。
加入位置编码:因为Transformer本身没有空间位置概念,所以需要为每个图像块添加位置编码,以保留其空间信息。
送入Transformer编码器:将这些带位置信息的向量序列输入一个标准的Transformer编码器(多头自注意力机制 + 前馈网络)进行处理。
分类头:取第一个特殊标记(
[class] token)对应的输出,用于最终的图像分类。
入门建议:
重点理解“图像分块”和“位置编码”这两个将图像适配到Transformer的关键步骤。
将ViT的流程与BERT处理句子的流程进行对比,你会发现惊人的相似性。
注意局限性:ViT在大规模数据集(如ImageNet-21K)上预训练后才能发挥巨大威力,在小数据集上可能不如精心设计的CNN。
三、学习路径建议
动手顺序:ResNet -> YOLO -> ViT。这个顺序符合从基础到前沿、从理解到应用的学习曲线。
实践为王:
对ResNet:在CIFAR-10小数据集上,尝试复现一个简化的ResNet(如20层),并与普通CNN对比。
对YOLO:务必使用官方代码和预训练模型,在你自己拍的图片或视频上跑一跑检测,这是建立成就感最快的方式。
对ViT:在Hugging Face的
transformers库中,调用ViTForImageClassification模型,体验其使用方式。
建立联系:思考ViT的注意力图能否解释模型关注了图像的哪部分?这和你做NLP的可解释性分析是相通的。
